

ทดลองใช้ PyCaret ที่ช่วยให้เราสร้าง Machine Learning แบบง่ายๆ หรือ Low-code Machine Learning
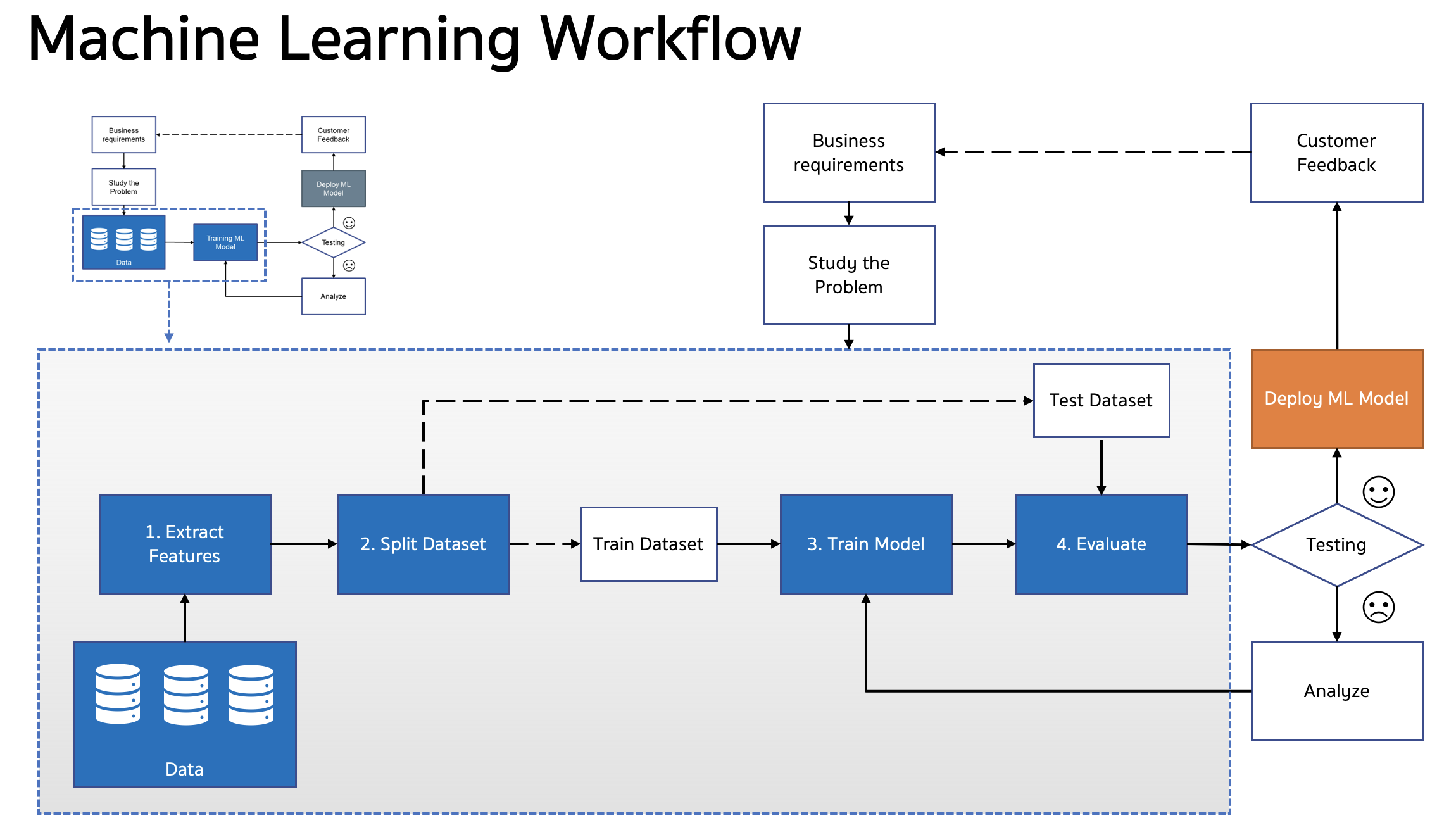
ปกติขั้นตอนการสร้าง Machine Learning Model นั้น มีขั้นตอนหลักๆ คือ
- Data Cleansing
- Extract Features
- Split dataset
- Select Algorithm
- Train the Model
- Evaluate with Train / Validation set
- Analyze the result
- A/B Testing
- Deploy
โดยขั้นตอนการ Train Model นั้นตามปกติแล้วในขั้นตอนที่ 4–7 เป็น Loop ที่เราควรจะใช้ Algorithm หลายๆ ตัวเทียบกัน เช่นถ้าเป็นโจทย์ Binary เราก็อาจจะลองทั้ง Logist Regression, XGBoost, Disicion Tree เป็นต้น ทำการ Hyper Parameter Tuning แล้วหลังจากนั้นเราก็ทำการ Compare ผลลัพธ์จากทุก Model ที่เราสร้าง แต่ วันนี้เราสามารถทำเรื่องเหล่านี้ ง่ายๆ ด้วย Library ที่ชื่อว่า PyCaret ครับ
PyCaret คืออะไร?
อย่างที่เคยเกริ่นไว้ PyCaret เป็น Python Library ที่ช่วยให้เราสร้าง Machine Learning Model ได้ง่ายขึ้นด้วย การทำงานแบบ Low-Code ตัว PyCaret จะช่วยเรา Train Model ด้วย Framework ชั้นนำที่เรารู้จักกันดี ไม่ว่าจะเป็น scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray เป็นต้น
นอกจากการ Train Model แล้ว PyCaret ยังช่วยวิเคราะห์ Analyze Model Performance ให้เราและเลือก Model ที่ดีที่สุดให้เราอีกด้วย ไปจนถึงการ Deploy Model ของเราบน Production อีกต่างหากช่วยให้เราลดงานการเขียนโปรแกรมลง
รายละเอียดเพิ่มเติมเกี่ยวกับ PyCaret
https://pycaret.org/
https://github.com/pycaret
ทดลองใช้งาน PyCaret, Predict Customer Churn
เดี๋ยววันนี้ผมจะมาลองใช้งาน PyCaret เพื่อ Predict Customer Churn สร้าง Model เพื่อ Predict ว่าลูกค้าคนไหนจะเลิกใช้บริการของเราในอนาคต Data ที่ใช้ คือ Telco Customer Churn ที่สามารถ Download จาก Kaggle นะครับ
ติดตั้ง PyCaret
pip install pycaretImport Libraries and Load the data
import pandas as pd
import numpy as np
import plotly.express as px#Read csv data
df=pd.read_csv('data/WA_Fn-UseC_-Telco-Customer-Churn.csv')
df.head()Data Cleansing
เปลี่ยน TotalCharges ให้เป็น Numeric ด้วยคำสั่งนี้ครับ
df["TotalCharges"] = pd.to_numeric(df["TotalCharges"], errors="coerce")โดยข้อมูลที่เราต้องการ Predict คือ Column Churn ที่หมายถึงตัวที่ระบุว่า ลูกค้าเลิกซื้อสินค้าหรือไม่ Yes = ยกเลิก, No = ไม่ยกเลิก ถ้าดูกราฟ จะเห็นว่า Data เป็น Imbalance Dataset หรือ Yes / No มีจำนวน Record ที่แตกต่างกันนั่นเอง
sns.countplot(x='Churn', data=df)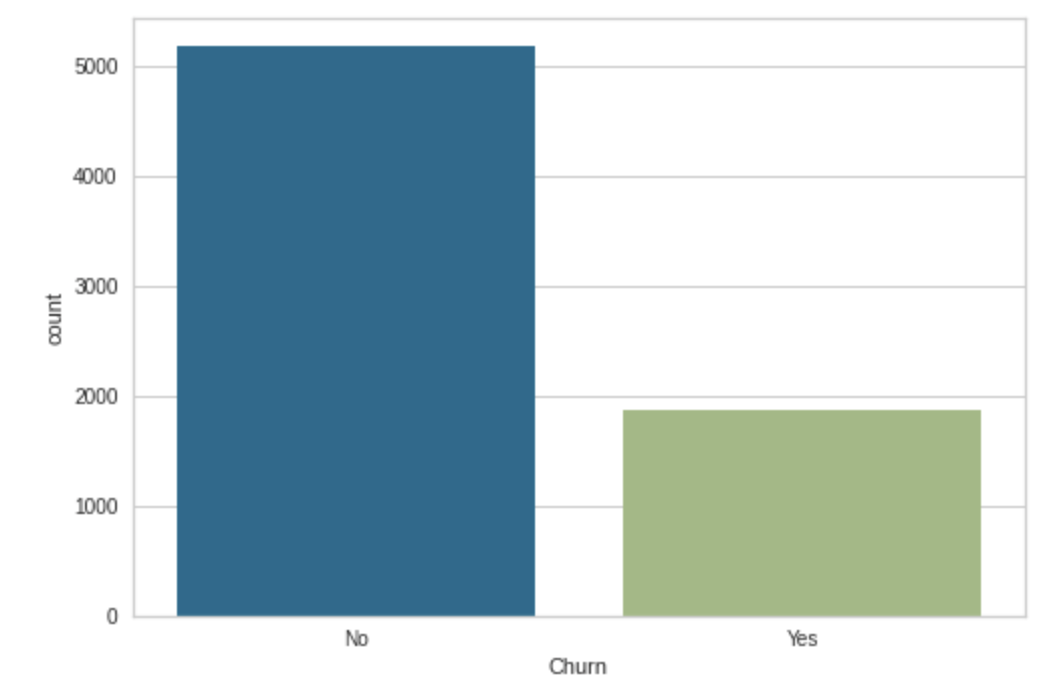
Setup PyCaret
Clean data พอเป็นพิธี เดี๋ยวเรามาลองใช้ PyCaret ในการสร้าง Model ดูครับ ใช้ Code ข้างล่าง แล้วก็ตรวจสอบ Data Type ถ้า OK แล้วก็กด Enter ในกล่อง input ใต้ ตารางครับ ตัว PyCaret ก็จะเริ่ม Train Model ให้เราทันที (ตรงกล่องสีฟ้าๆ ในรูป)
#Setup PyCaret and Run
# init setup
from pycaret.classification import *
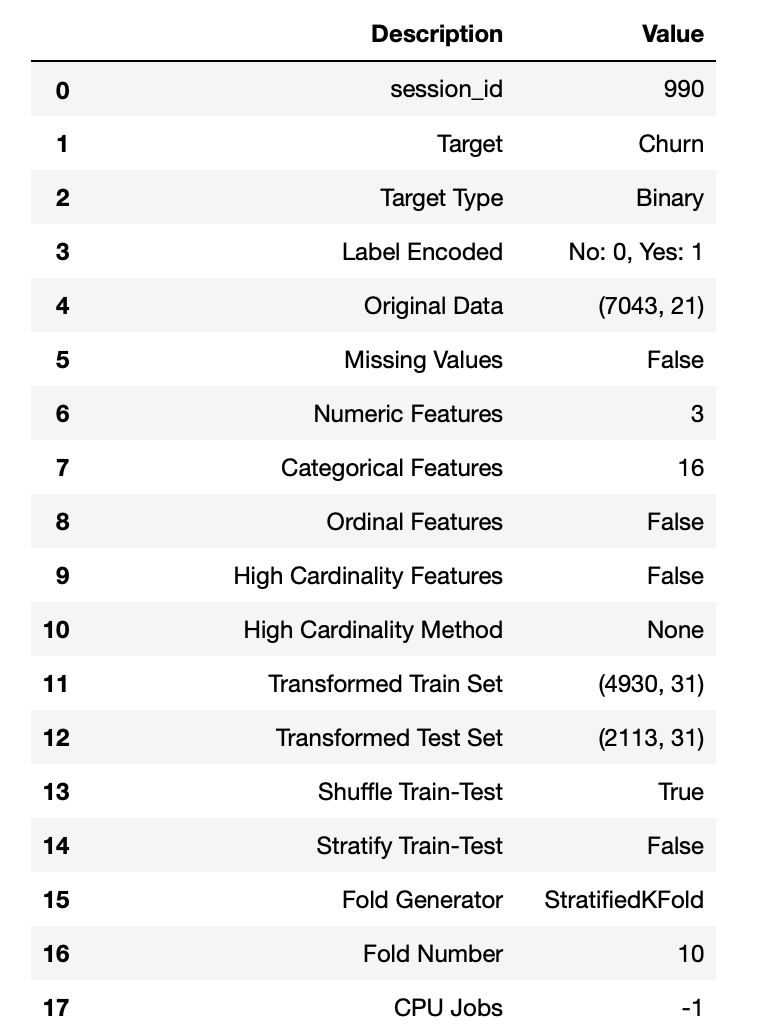
s = setup(df,
target = 'Churn',
normalize=True,
remove_outliers=True,
fix_imbalance=True,
ignore_features = ['customerID'])ปล.ถ้าสังเกตใน setup ผมใส่ Parameter ให้ทำการ normalize data ด้วย ให้ Remove outlier แก้ไข imbalance data และให้ ignore field customerID ที่ไม่ได้มีผลต่อการ Train Model ครับ
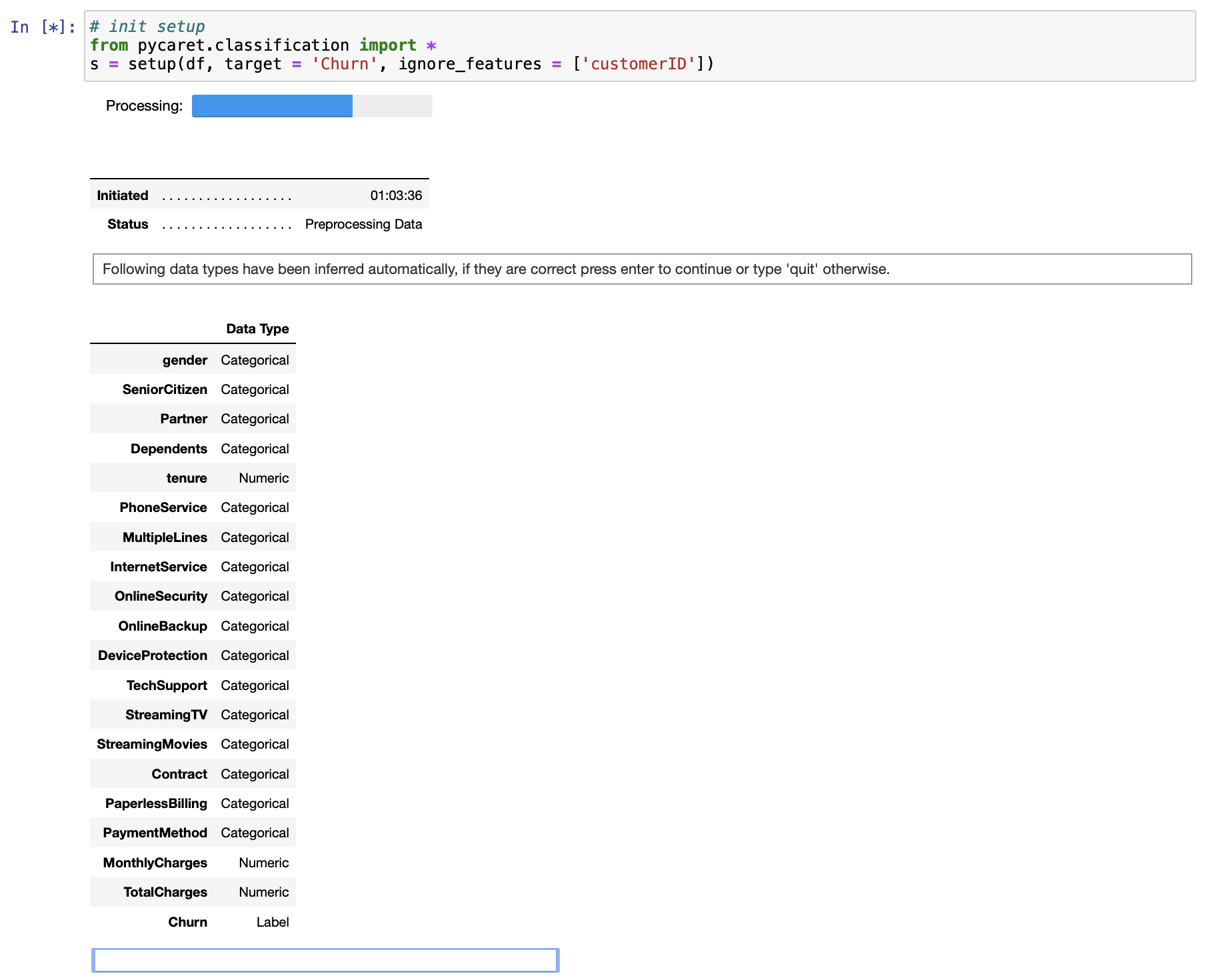
พอ PyCaret ทำงานเสร็จแล้วก็จะเห็นหน้าตา Output ประมาณนี้ครับ
Evaluate Model Performance
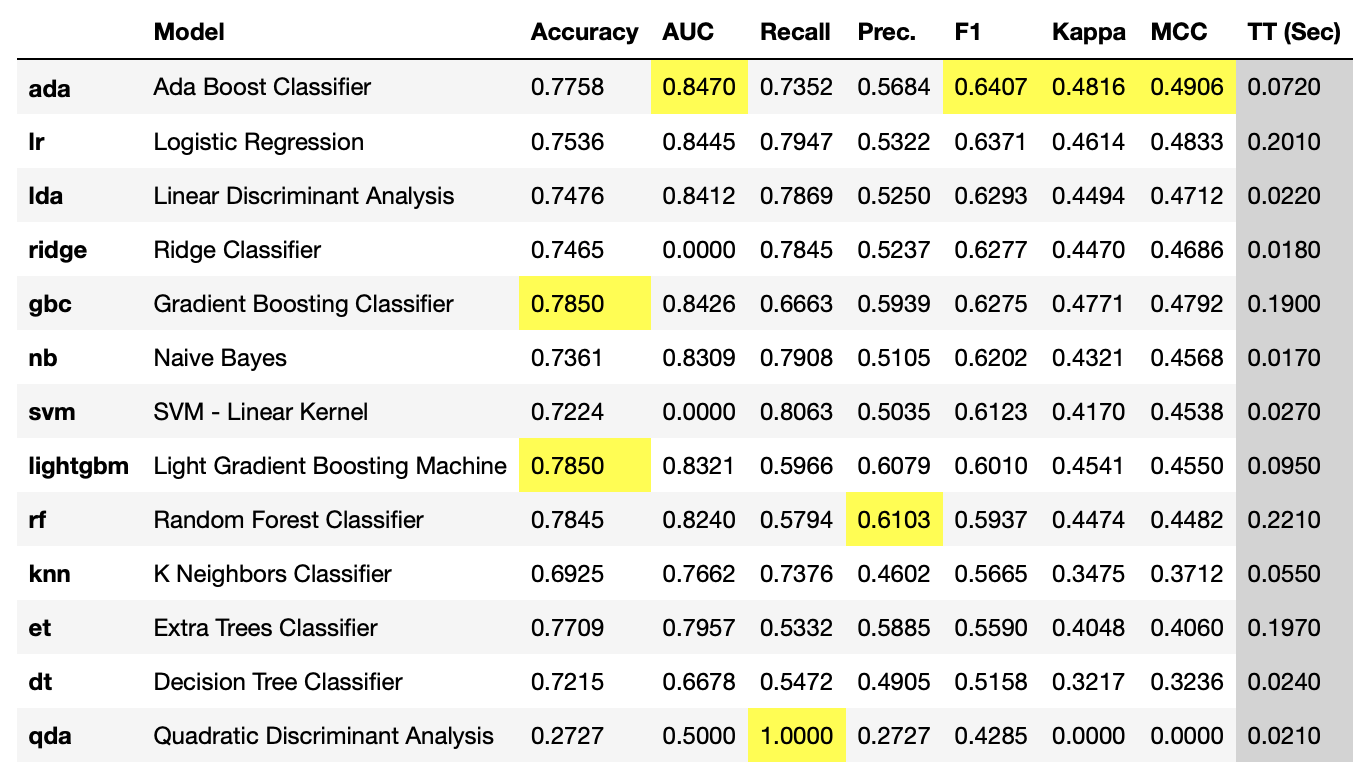
คราวนี้เรามาดูผลลัพธ์ของ แต่ละ Model กันครับ ในตัวอย่างนี้จะดู F1 Score เป็นหลัก เพราะ data เป็น imbalance dataset โจทย์นี้ Recall & Presicion สำคัญครับ โดยใช้คำสั่ง
best_model = compare_models(sort='F1')ถ้าดูจากรูป จะเห็นว่า Model ที่ได้ค่า F1 สูงที่สุดคือ Ada Boost Classifier ครับ ได้ F1 Score = 0.6407
Hyper Parameter Tuning
โดยที่ PyCaret ยังสามารถช่วยให้เราทำ Hyper Parameter Tuning ได้ง่ายๆ ด้วยเช่นกัน
tuned_best_model = tune_model(estimator=best_model, optimize="F1")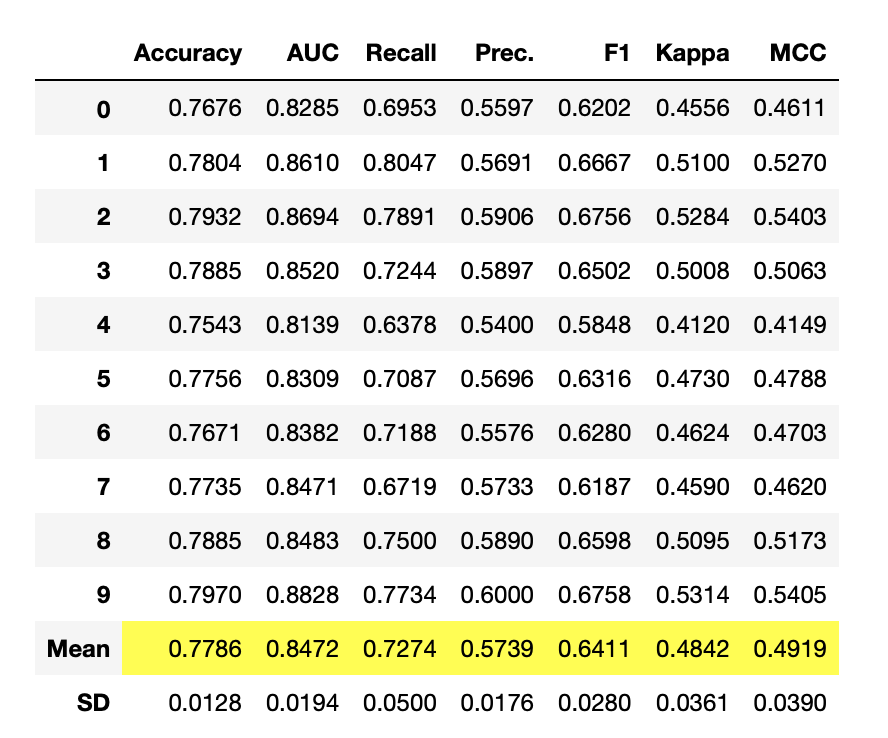
หลังการทำ Hyper Parameter Tuning ตัว F1 เพิ่มขึ้นนิดหน่อย จาก 0.6407 เป็น 0.6411 ใช้ได้ๆ เขียนโค้ด บันทัดเดียว
Model Performance
นอกจากนั้นยังไม่พอนะครับ PyCaret ยังสามารถ Plot graph Model Performace ให้เราดูได้ง่ายๆ ด้วย ไม่ว่าจะเป็น AUC Curve, Confusion Matrix, Feature Importance และอื่นๆ อีกมากครับ
# AUC Plot
plot_model(tuned_best_model, plot = 'auc')
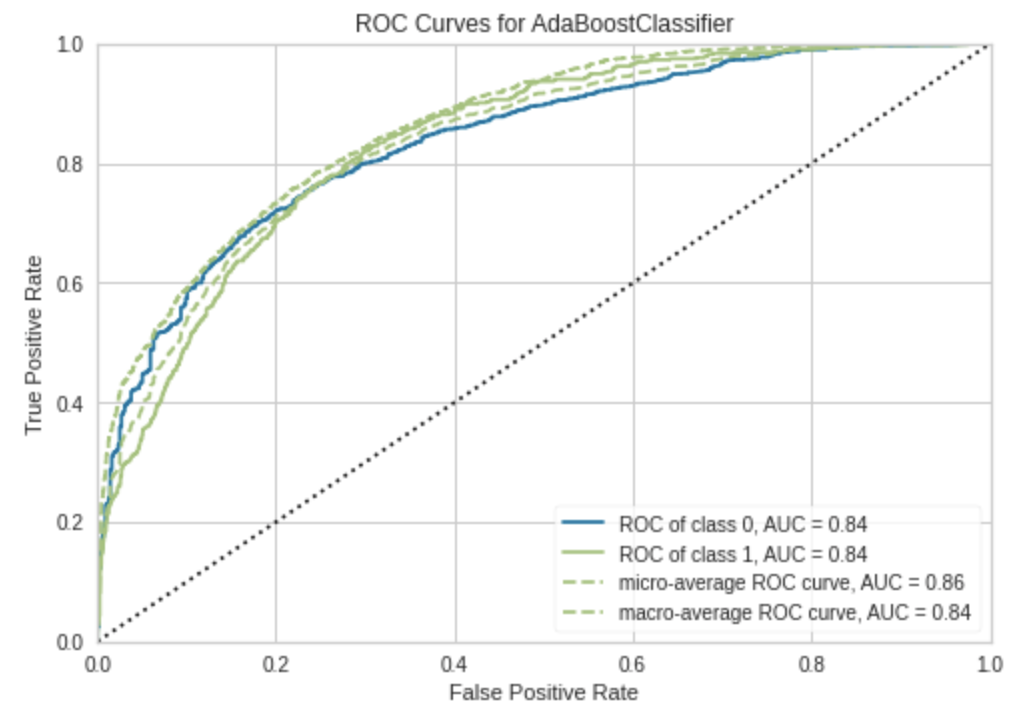
AUC ของแต่ละ Class ได้ 0.84 ถือว่า Model ทำงานได้ดีเลยครับ
plot_model(tuned_best_model, plot="pr")
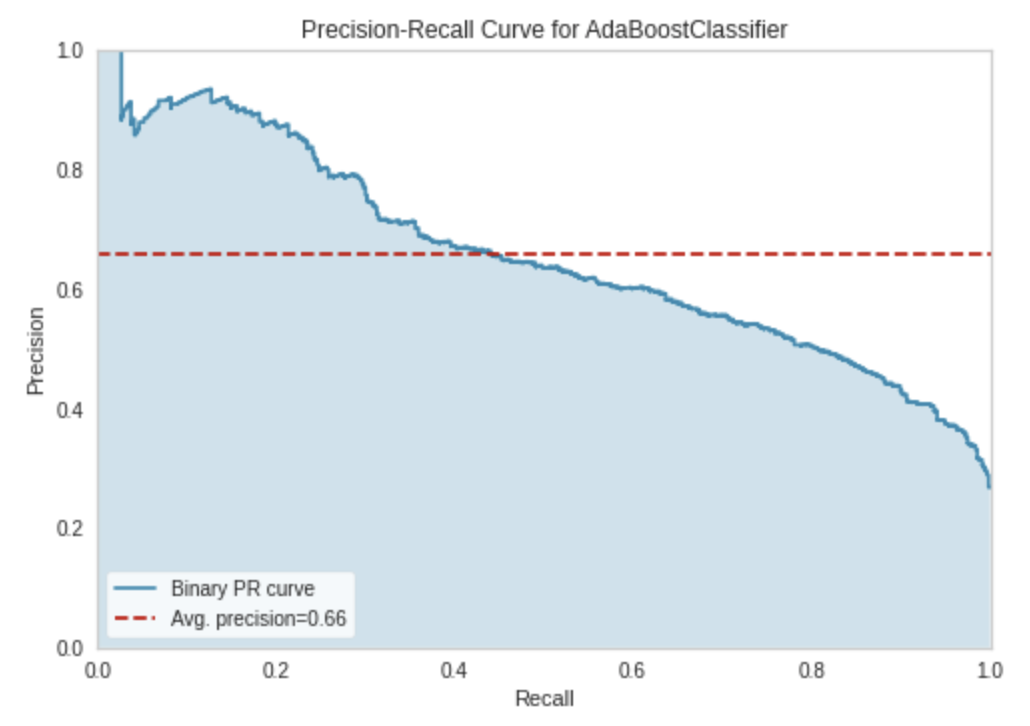
Precision — Recall Curve ได้ค่าเฉลี่ย 0.66 ก็ถือว่า ok เลย่นะครับ
# Confusion Matrix
plot_model(tuned_best_model, plot = 'confusion_matrix')
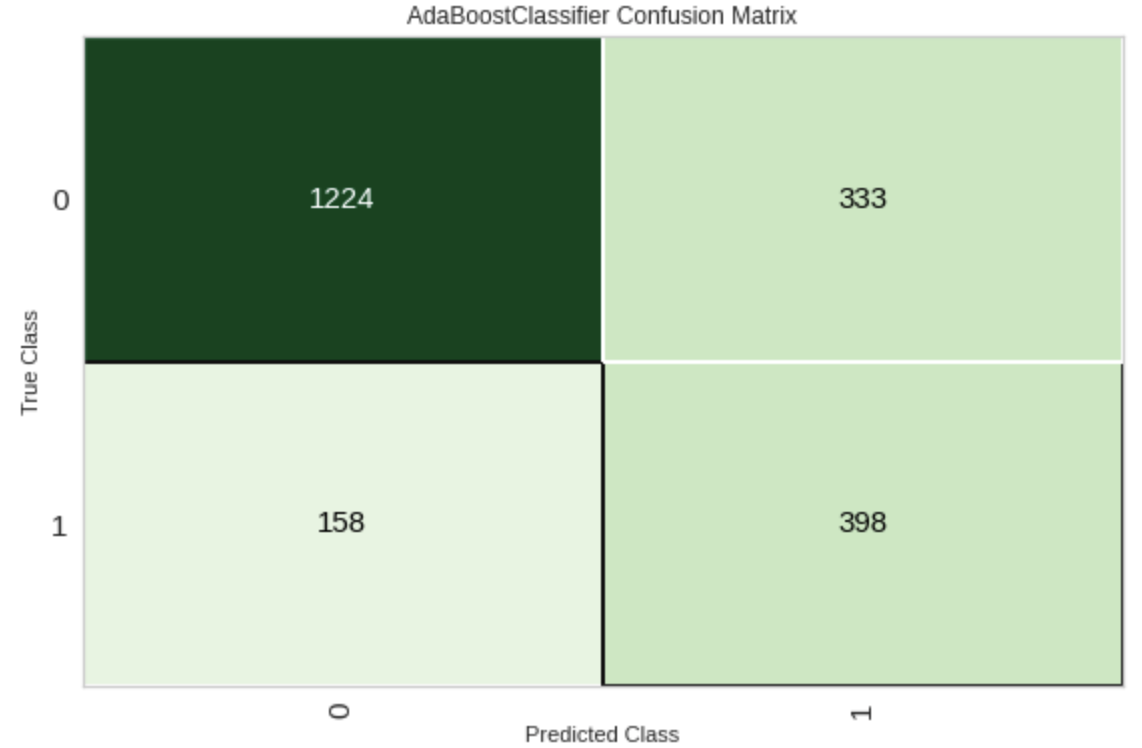
ถ้าดู Confusion Matrix จะเห็นว่า มี 333 คนที่ Model Predict ว่า Churn แต่จริงๆ แล้ว ไม่ Churn แต่ถ้า Predict ว่าใครจะไม่ Churn บ้างนี้ ค่อนข้างแม่นเลยครับ ทายถูก 1224 คน
แต่ถ้าดูจริงๆ แล้ว มีถึง 398 คนที่ Model ทำนายว่าลูกค้าจะยกเลิกสัญญา และยกเลิกจริงๆ ซึ่งถ้าหากเราทำ Campaign ส่งเสริมการขาย ให้กับลูกค้ากลุ่มนี้ จะทำให้เราสามารถ บริหารจัดการค่าใช้จ่ายได้ง่ายขึ้น โดยที่เราไม่จำเป็นต้องทำกับลูกค้าทุกคน
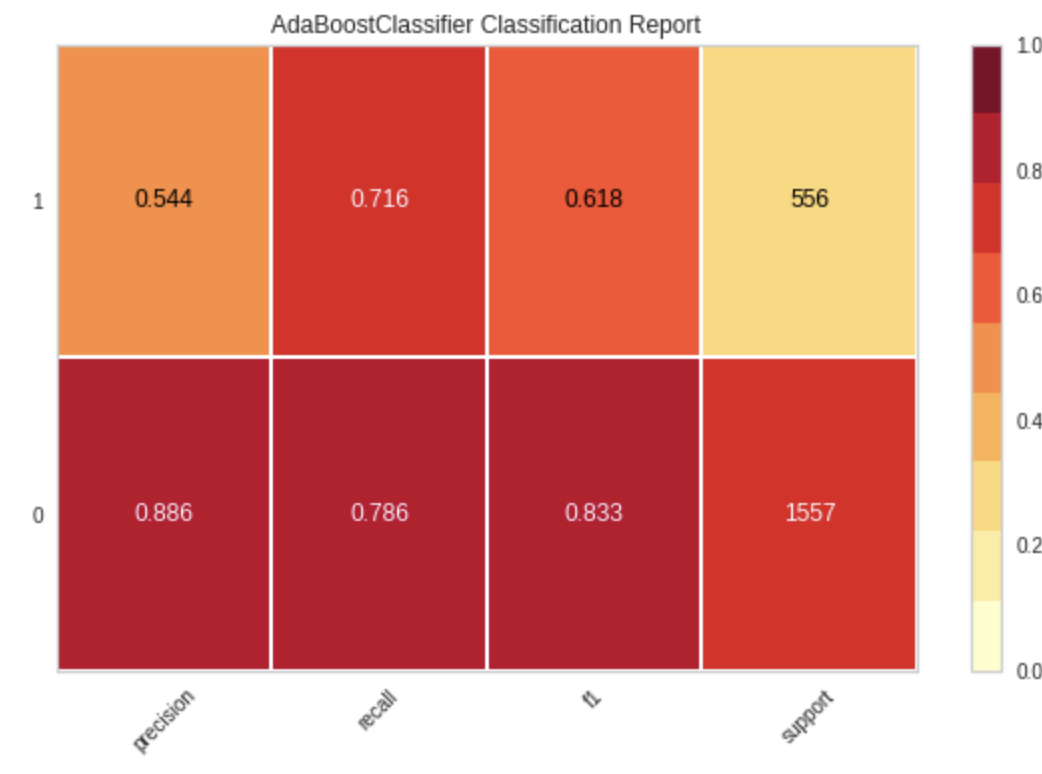
โมเดลทำงานได้ค่อนข้างดี แต่ Precision 0.544 ในการ Preduct ว่าลูกค้าจะ Churn
นอกจากนั้นยังไม่พอ เรายังสามารถ Plot Feature Importance ได้ง่ายเลยครับ
# Feature Importance Plot
plot_model(tuned_best_model, plot = 'feature')
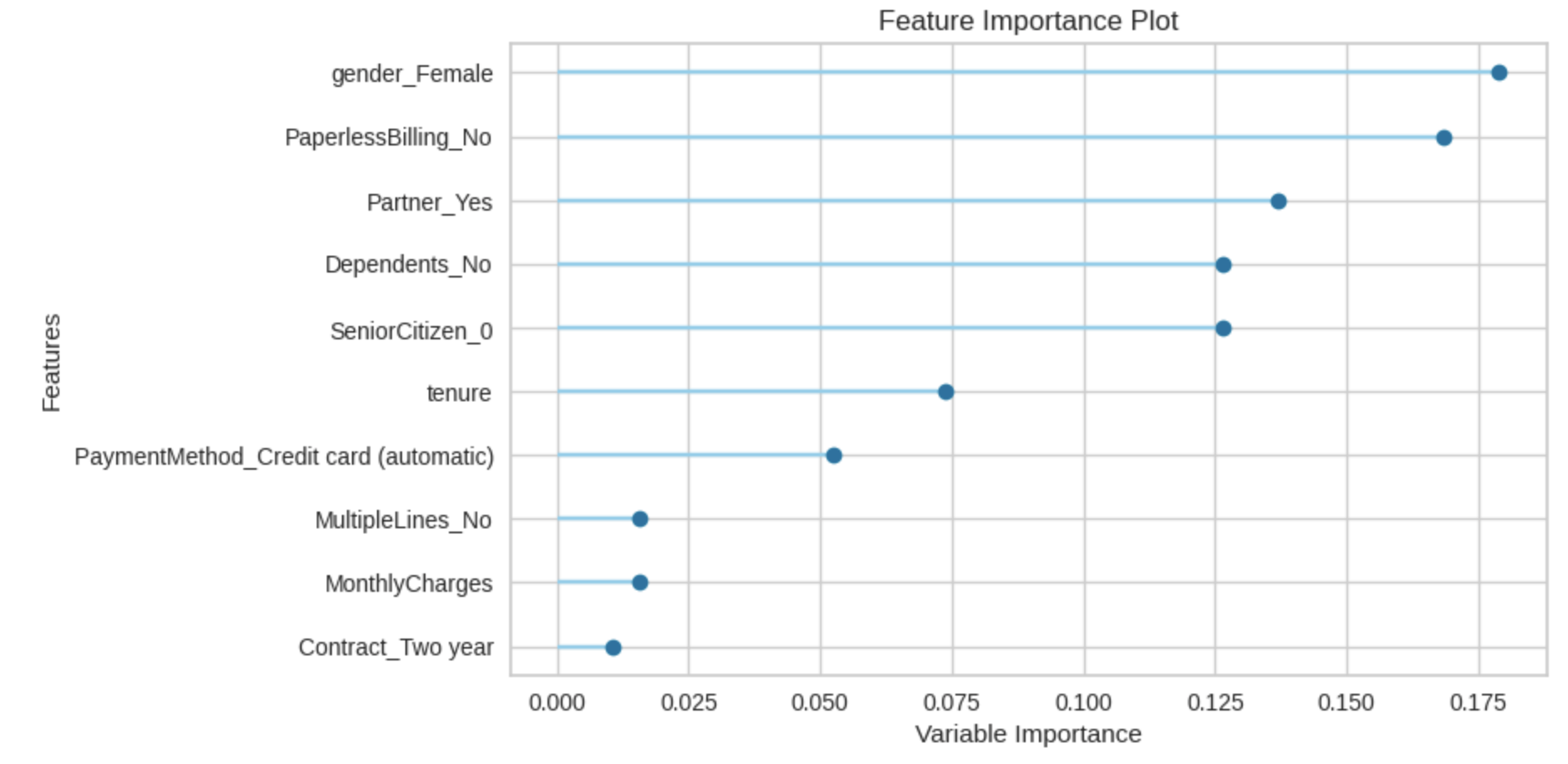
จะเห็นว่า Feature ที่มีผลต่อการ ยกเลิก หรือ Churn คือ gender_Female, PaperlessBilline_No อันนี้ก็สามารถเอาไปวิเคราะห์เชิงลึกต่อได้ว่า ถ้าลูกค้าเปลี่ยนมาใช้ Paperless Billing แล้วจะทำให้ลูกค้าใช้บริการต่อ เราก็สามารถ Push marketing activity ต่อไปได้ เป็นต้น
ถือว่าใช้ได้ครับ สำหรับ PyCaret สามารถช่วยลดเวลาในการเขียน Code ได้เยอะเลย ถ้าสนใจก็เข้าไปดู Code ได้ที่ GitHub ของผมได้เลยครับ
สำหรับคนที่สนใจเพิ่มเติมก็เข้าไปดูได้ที่ Post นี้นะครับ ผมปรับโค้ดจากของเค้านิดหน่อย
PyCaret Reference: