
Claude Opus 4.7 ไม่ได้แค่เก่งขึ้น แต่ Anthropic กำลังส่งสัญญาณว่า Mythos อยู่ไม่ไกลอย่างที่คิด
ถ้าดูแบบผิวเผิน ข่าวนี้คือเรื่องง่ายมาก
Anthropic เปิดตัว Claude Opus 4.7 มันเก่งขึ้นจาก Opus 4.6 ราคาเท่าเดิม และเป็นโมเดล generally available ที่ดีที่สุดของบริษัท ณ ตอนนี้
แต่ถ้าอ่าน launch page ดีๆ จะมีประโยคหนึ่งที่ทำให้ข่าวนี้ใหญ่ขึ้นทันที
Anthropic เขียนเองว่า แม้ Opus 4.7 จะเป็นโมเดล generally available ที่เก่งที่สุดของเขา แต่ มันยังด้อยกว่า Claude Mythos Preview โดยรวม
ประโยคนี้ทำให้เรื่องเปลี่ยนจาก “รุ่นใหม่ออกแล้ว” ไปเป็น “Anthropic กำลังเปิดให้ตลาดเห็นชั้นของ capability ที่ยังไม่ปล่อยเต็ม”
และนี่แหละคือมุมที่น่าสนใจกว่า product update ธรรมดา
Why chosen
- Pattern family ที่อิง: claude_ecosystem พร้อมแรงหนุนจาก ai_dev_tools
- Why now: Opus 4.7 เปิดตัววันที่ Apr 16, 2026 ตามทั้ง release notes และหน้า Claude Opus อย่างเป็นทางการ และเป็นข่าวที่มีผลกับทั้งคนใช้ Claude, ทีม dev, และคนที่กำลังติดตามทิศทาง frontier model
- Why this angle: แทนที่จะเล่าซ้ำว่า Opus 4.7 ดีขึ้นยังไงอย่างเดียว ผมเลือกมุม what changed + roadmap signal เพราะจุดที่แรงกว่าคือ Anthropic ยอมเทียบกับ Mythos Preview ใน benchmark table เดียวกัน ซึ่งเผยให้เห็นสิ่งที่ยัง “ไม่ปล่อยกว้าง” มากกว่าที่บริษัทมักยอมพูดกัน
1) Opus 4.7 คือ upgrade จริง และ Anthropic พูดชัดว่ามันคือ best GA model ของบริษัท
ทั้งหน้า release notes และหน้า product overview ของ Anthropic พูดตรงกันว่า Claude Opus 4.7 คือ
- โมเดล generally available ที่เก่งที่สุดของบริษัท
- เน้น complex reasoning และ agentic coding
- ราคาเท่า Opus 4.6 คือ $5 ต่อ input MTok และ $25 ต่อ output MTok
- ใช้ได้ทั้งใน Claude products, API, Bedrock, Vertex AI และ Foundry
หน้า “What’s new in Claude Opus 4.7” ยังระบุชัดด้วยว่า ของใหม่ที่สำคัญคือ
- high-resolution image support สูงสุด 2576px / 3.75MP
- effort level ใหม่ชื่อ
xhigh - task budgets
- 1M context window
- 128k max output
- adaptive thinking แทน extended thinking เดิม
ดังนั้นถ้ามองในเชิง product จริงๆ Opus 4.7 ไม่ใช่ minor refresh แน่ มันคือการอัปเกรด capability พร้อม behavior change และ API migration impact ไปพร้อมกัน
2) แต่จุดที่สะเทือนกว่าคือ Anthropic ยอมพูดชัดว่า Mythos Preview แรงกว่า
ประโยคนี้ในหน้าเปิดตัวสำคัญมาก:
although it is less broadly capable than our most powerful model, Claude Mythos Preview
นี่ไม่ใช่คำโปรยเล็กๆ เพราะมันเท่ากับ Anthropic กำลังแยกชั้นของ portfolio ตัวเองอย่างชัดเจนว่า
- Opus 4.7 = best broadly available model
- Mythos Preview = stronger but still gated / limited-release model
ในโลก AI frontier เรื่องนี้สำคัญมาก เพราะมันเปิดให้เห็นว่าโมเดลที่บริษัท “ขายให้ตลาดทั่วไป” กับโมเดลที่บริษัท “เก็บไว้ใช้งานแบบจำกัด” อาจห่างกันไม่มากอย่างที่คนคิด
หรือพูดอีกแบบ ข่าวนี้ไม่ได้บอกแค่ว่า Opus 4.7 มาถึงไหน แต่มันบอกอ้อมๆ ว่า Mythos ไปไกลแค่ไหนแล้ว
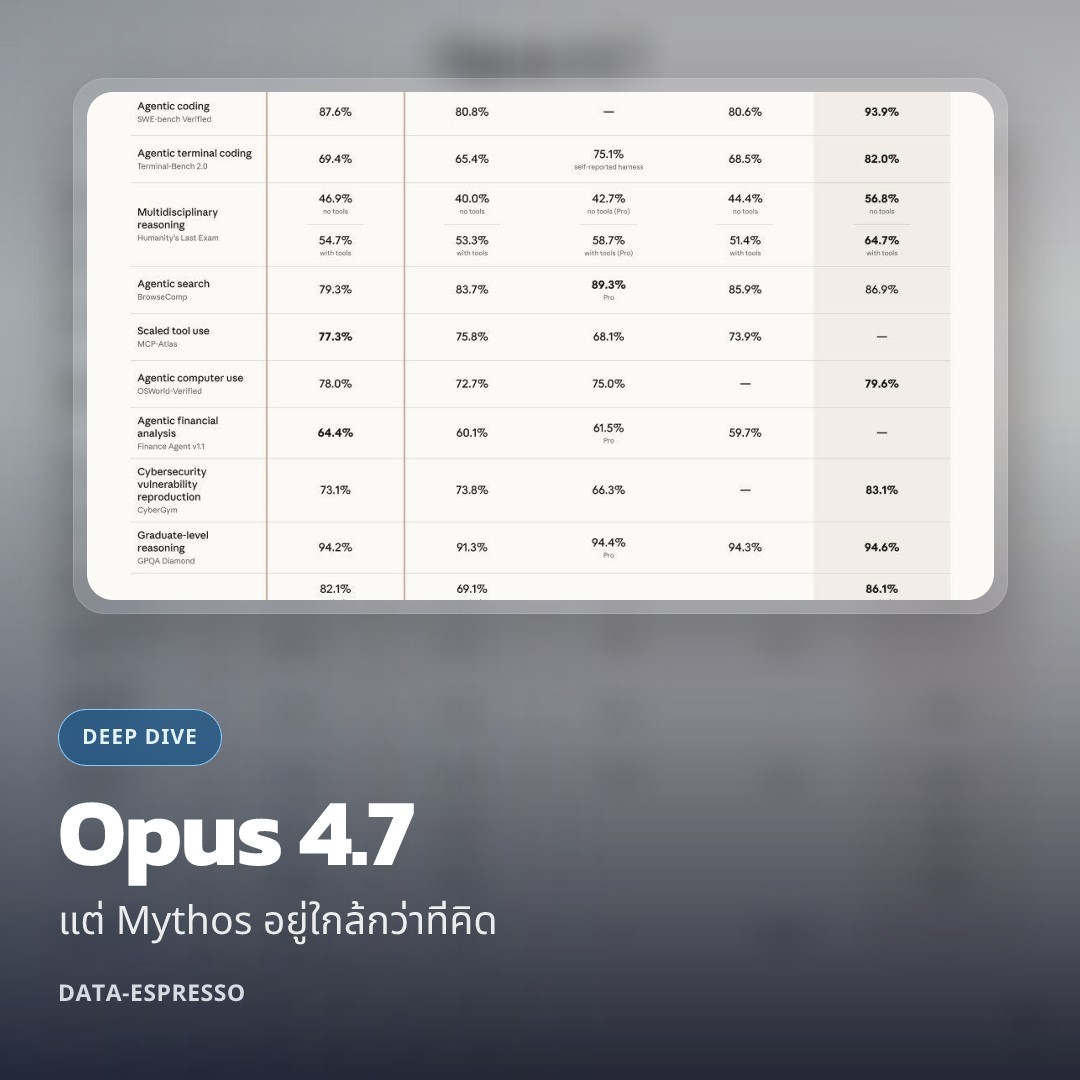
3) ตาราง benchmark ทำให้ Mythos ไม่ใช่แค่ชื่อหลุด, แต่มีรูปร่างจริง
ใน launch materials ของ Opus 4.7 Anthropic แนบ benchmark table ที่วาง Opus 4.7 เทียบกับ Opus 4.6, GPT-5.4, Gemini 3.1 Pro และ Mythos Preview ในตารางเดียวกัน
นี่คือสิ่งที่น่าตกใจสำหรับผม เพราะทันทีที่ Mythos โผล่ในตาราง มันกลายเป็น “reference class” ไม่ใช่แค่ข่าวลือหรือ internal codename แล้ว
จากตารางที่ Anthropic ใช้ประกอบการเปิดตัว เราเห็นภาพคร่าวๆ แบบนี้:
- Agentic coding (SWE-bench): Opus 4.7 = 64.3%, Mythos Preview = 77.8%
- Agentic coding (SWE-bench Verified): Opus 4.7 = 87.6%, Mythos Preview = 93.9%
- Agentic terminal coding (Terminal-Bench 2.0): Opus 4.7 = 69.4%, Mythos Preview = 82.0%
- Cybersecurity vulnerability reproduction (CyberGym): Opus 4.7 = 73.1%, Mythos Preview = 83.1%
แต่ขณะเดียวกันก็มีหลายหมวดที่ช่องว่างเริ่มแคบมาก เช่น
- Agentic computer use (OSWorld-Verified): 78.0% vs 79.6%
- Graduate-level reasoning (GPQA Diamond): 94.2% vs 94.6%
- Visual reasoning (with tools): 91.0% vs 93.2%
นี่ทำให้ภาพเริ่มชัดมากว่า Mythos ไม่ได้เหนือกว่าแบบทิ้งห่างทุกมิติเท่ากัน แต่มีบางโซนที่มันยังนำโดดเด่น โดยเฉพาะสาย agentic coding ระดับหนักและ cybersecurity
4) สิ่งที่น่าสนใจคือ Opus 4.7 ดูเหมือน “general frontier model” ที่พยายามเข้าใกล้ Mythos โดยไม่ปล่อย cyber capability เต็มมือ
Anthropic ผูกเรื่องนี้เข้ากับ Project Glasswing โดยตรง
ในหน้าเปิดตัว Opus 4.7 บริษัทอธิบายว่า Mythos Preview ยังถูกจำกัด release เพราะ capability ด้าน cybersecurity สูงมาก และ Opus 4.7 คือโมเดลแรกที่ใช้เป็นสนาม deploy safeguard ก่อนสำหรับ model class ที่ต่ำกว่า Mythos
Anthropic ยังบอกด้วยว่า ระหว่าง training ของ Opus 4.7 มีการทดลอง ลด capability ด้าน cyber แบบเฉพาะทาง ลงด้วย
ถ้าตีความเชิงกลยุทธ์ นี่แปลว่า Anthropic ไม่ได้แค่ออกโมเดลใหม่ แต่กำลังพยายามหาสมดุล 3 อย่างพร้อมกัน:
- ปล่อย model ที่เก่งพอจะชนะตลาดในงานทั่วไป
- ไม่ปล่อย capability ที่อาจเสี่ยงเกินไปแบบ Mythos กว้างๆ
- ใช้ Opus 4.7 เป็นพื้นที่ทดลอง safeguard ก่อนวันหนึ่งจะไปถึง Mythos-class release
มุมนี้สำคัญมากสำหรับคนดูสงครามโมเดล เพราะมันบอกว่า frontier competition ต่อจากนี้อาจไม่ใช่แค่ “ใครเก่งกว่า” แต่คือ “ใครปล่อย capability ได้เร็วโดยไม่ชนเพดานความเสี่ยงก่อน”
5) ถ้ามองเป็น product strategy, Anthropic กำลังทำ portfolio segmentation แบบชัดขึ้นมาก
ผมคิดว่าข่าวนี้ควรถูกอ่านในมุม product portfolio ด้วย
ตอนนี้ Anthropic มีชั้นของข้อเสนอชัดขึ้นเรื่อยๆ
- Haiku = speed / cost
- Sonnet = balanced workhorse
- Opus 4.7 = best generally available frontier model
- Mythos Preview = gated research preview สำหรับงาน defensive cybersecurity
การวางแบบนี้ฉลาดมาก เพราะมันทำให้ Anthropic รักษาความได้เปรียบสองชั้นพร้อมกัน
ชั้นแรก: commercial layer
ลูกค้าทั่วไปได้ Opus 4.7 ที่แรงพอมากสำหรับงานจริง
ชั้นสอง: strategic reserve layer
Anthropic ยังเก็บ Mythos-class capability ไว้ใน controlled rollout ไม่ต้องปล่อยทุกอย่างสู่ตลาดทันที
ตรงนี้คล้ายการที่บริษัทเริ่มมี “top secret tier” แบบไม่ต้องเรียกว่าท็อปลับตรงๆ และแค่การยอมเทียบใน benchmark table ก็เพียงพอจะสร้างแรงกดดันทาง perception ต่อคู่แข่งแล้ว
6) สิ่งที่ Opus 4.7 สะท้อน ไม่ใช่แค่ benchmark ชนะขึ้น แต่คือการขยับไปสู่ long-horizon reliability
อีกมุมที่ผมคิดว่าสำคัญมากจากทั้ง release page และ customer quotes คือ Anthropic กำลังขาย Opus 4.7 ด้วยคำว่า
- long-running tasks
- autonomy
- consistency
- instruction following
- self-verification
- fewer tool errors
- better memory across sessions
นั่นแปลว่า Opus 4.7 ไม่ได้ถูกขายในฐานะ “โมเดลตอบเก่ง” อย่างเดียวแล้ว แต่มันถูกวางเป็น execution model สำหรับงานยาว, งานซับซ้อน, และงานที่ต้องอยู่ใน loop กับ tools จริงๆ
ถ้าเชื่อมกับ Mythos ที่เด่นเรื่อง cyber และ vulnerability work ภาพรวมจะยิ่งชัดว่า Anthropic กำลังเดินไปในทิศทางของโมเดลที่ทำ “real operational work” ได้มากขึ้นเรื่อยๆ ไม่ใช่แค่ฉลาดขึ้นในแชต
7) แล้วเราควรอ่านคำว่า “ใกล้ Mythos” ยังไงให้ไม่เกินจริง
ผมคิดว่าต้องระวัง 2 เรื่อง
เรื่องที่ 1: ใกล้ ไม่ได้แปลว่าเท่ากัน
จาก benchmark table จะเห็นว่ามีหลายหมวดที่ Mythos ยังนำพอสมควร โดยเฉพาะสาย coding แบบหนักและ cyber
เรื่องที่ 2: Mythos เป็น research preview ที่มีขอบเขตการใช้งานแคบกว่า
มันไม่ได้ถูกปล่อยให้ตลาดทั่วไปใช้อย่าง Opus 4.7 ดังนั้นการเทียบ capability อย่างเดียวโดยไม่มอง deployment policy จะทำให้ตีความผิดได้ง่าย
พูดอีกแบบคือ Opus 4.7 ใกล้ Mythos ในแง่ที่ “เราเริ่มมองเห็นขอบของโมเดลชั้นถัดไป” แต่ยังไม่ใช่ว่า Anthropic ปล่อย Mythos-class capability ออกสู่ตลาดกว้างแล้ว
8) สิ่งที่ทีม dev และผู้บริหารควรเก็บจากข่าวนี้
1. ถ้าคุณใช้ Claude อยู่แล้ว Opus 4.7 ไม่ใช่ optional upgrade ธรรมดา
เพราะมีทั้ง capability jump และ migration impact ระดับ API / prompt / token behavior
2. Benchmark table นี้บอกมากกว่า performance
มันบอก portfolio strategy และ release strategy ของ Anthropic ด้วย
3. Mythos คือ signal ว่าขอบบนของ capability ไปไกลกว่าที่ปล่อยขายแล้ว
ดังนั้น roadmap ของงาน agentic และ cyber AI จะร้อนขึ้นอีกมากในช่วงต่อจากนี้
4. การปล่อย model ต่อจากนี้จะผูกกับ safety gating มากขึ้น
โดยเฉพาะใน domain ที่แตะ cyber, autonomy, และ high-risk operations
บทสรุป
ถ้าจะสรุปแบบ Data-Espresso ในประโยคเดียว ผมจะพูดว่า
Claude Opus 4.7 คือข่าวเปิดตัวรุ่นใหม่ แต่ Mythos ที่โผล่มาใน benchmark table คือข่าวใหญ่กว่านั้น เพราะมันเผยให้เห็นว่าของที่ Anthropic ยังไม่ปล่อยกว้าง ไปไกลแค่ไหนแล้ว
และนี่ทำให้เรื่องนี้มีความหมายมากกว่าคำว่า “Opus 4.7 แรงขึ้น”
มันคือสัญญาณว่า frontier model roadmap เริ่มถูกแบ่งเป็นสองโลกชัดขึ้น:
- โลกของโมเดลที่ขายได้ตอนนี้
- โลกของโมเดลที่บริษัทเก็บไว้เพราะ capability มันแรงเกินกว่าจะปล่อยง่ายๆ
Opus 4.7 อยู่โลกแรก Mythos ชี้ไปยังโลกที่สอง
และการที่ช่องว่างระหว่างสองโลกเริ่มเห็นได้ชัดจาก benchmark เดียวกัน นั่นแหละคือประเด็นที่ควรจับตาที่สุด
FAQ
Q1: Opus 4.7 สำคัญยังไงถ้ามองแบบสั้นๆ?
มันคือโมเดล generally available ที่ดีที่สุดของ Anthropic ตอนนี้ และเป็น direct upgrade จาก Opus 4.6 ที่ราคาเท่าเดิม แต่สิ่งที่ใหญ่กว่าคือ Anthropic ยอมวาง Mythos Preview เทียบใน benchmark เดียวกัน
Q2: Mythos Preview คืออะไร?
เป็น research preview model ของ Anthropic สำหรับ defensive cybersecurity work ภายใต้ Project Glasswing และยังเปิดแบบ invitation-only
Q3: Opus 4.7 ใกล้ Mythos จริงไหม?
ใกล้ขึ้นในหลายหมวด โดยเฉพาะบาง benchmark ทั่วไปและ visual reasoning แต่ Mythos ยังนำชัดในหลายหมวดสำคัญ โดยเฉพาะ agentic coding และ cybersecurity
Q4: Anthropic ปล่อย Mythos แล้วหรือยัง?
ยังไม่ปล่อยกว้าง Mythos Preview ยังถูกจำกัด release และใช้ในกรอบ defensive cybersecurity เป็นหลัก
Q5: บทเรียนสำหรับทีมที่ใช้ Claude คืออะไร?
อย่ามองแค่ benchmark ชนะหรือแพ้ ให้ดูด้วยว่า model behavior, tokenization, effort settings, vision fidelity, และ safety gating เปลี่ยน workflow จริงของคุณยังไง
รับคู่มือ Claude AI + บทความใหม่ก่อนใคร
สมัครรับจดหมายจากอาร์ตี้ — ไม่สแปม ไม่เกิน 1–2 ฉบับ/สัปดาห์