
OpenClaw 2026.6.10 beta: AI Agent ที่ใช้จริงต้องไม่ลืมงานกลางทาง
AI Agent ที่ใช้จริง ไม่ได้วัดกันแค่ว่า “ตอบฉลาดไหม” ครับ
แต่วัดกันว่า มันไม่ลืมงานกลางทางหรือเปล่า
วันที่ 21 มิถุนายน 2026 ตาม GitHub release metadata, OpenClaw ออก prerelease v2026.6.10-beta.1 โดย release นี้เน้นหลายจุดที่ดูเหมือนเรื่องระบบหลังบ้าน เช่น session state, subagent handoff, channel delivery, approval flow, queue drain, cron safety, provider fallback และ diagnostics
ฟังดู technical มาก แต่ถ้าแปลเป็นภาษาธุรกิจคือแบบนี้ครับ
เมื่อเราเริ่มใช้ AI Agent ทำงานจริง ไม่ว่าจะเป็น coding agent, AI coworker, chat automation, Slack/Telegram bot, cron job หรือ workflow ที่ต่อกับ MCP tools ความน่ากลัวไม่ได้มีแค่ “AI ตอบผิด”
แต่มันรวมถึงงานหายกลางทาง, retry แล้วซ้ำ, ส่งข้อความแล้วไม่มี proof, approval ไปผิดที่, context หลุดหลัง compact, model failover แล้วเงียบ, cron ส่งไปผิด target หรือ subagent ทำเสร็จแล้ว main agent ไม่รู้
นี่คือความต่างระหว่าง AI demo กับ AI operation ครับ
1) เกิดอะไรขึ้น
OpenClaw v2026.6.10-beta.1 เป็น prerelease ที่รวม PR จำนวนมาก แต่ถ้าดึงเฉพาะสัญญาณที่เกี่ยวกับการใช้งานจริง จะเห็น pattern ชัดมาก
Release note บอกว่า OpenClaw ปรับปรุงเรื่องเหล่านี้:
- pending subagent completion announcements ต้องถูก preserve ไม่หายระหว่าง handoff
- chat history transcript ต้องไม่กลายเป็น empty โดยไม่ควร
- media index alignment ต้องไม่สลับไฟล์, URL หรือ type ของ attachment
- dormant follow-up drains ต้อง restart ไม่ใช่ค้างเงียบ
- compaction model alias ต้อง resolve ไปยัง canonical model ref
- Codex approval, SecretRefs, thread context และ session helpers ต้อง predict ได้มากขึ้น
- Telegram, Discord, Slack ต้อง preserve progress, reasoning, thread output และ structured send errors
- SSH tunnel preflight ต้อง scoped ที่ loopback
- volatile SQLite state ต้อง surfaced ผ่าน doctor
- cron delivery บางรูปแบบต้องมี explicit target proof
- provider overload หรือ unsupported model refs ต้อง failover หรือปฏิเสธแบบชัด ไม่ใช่เงียบ
ผมมองว่านี่ไม่ใช่แค่ “bug fixes เยอะ”
แต่มันคือภาพจริงของ agent product ที่กำลังโตขึ้นครับ
พอ agent เริ่มทำงานหลายขั้นตอน หลายช่องทาง หลาย model หลาย tool และหลาย session ความเสี่ยงจะย้ายจาก “model ฉลาดพอไหม” ไปเป็น “ระบบรอบ model คุม state, handoff, approval และ recovery ได้ไหม”
2) ทำไมเรื่องนี้สำคัญกับธุรกิจไทย
ลองนึกภาพง่าย ๆ ครับ
คุณมี AI Agent ที่ช่วยทีมขายตอบ lead ผ่าน LINE หรือ Facebook แล้วส่ง follow-up ผ่าน CRM
ถ้า agent ตอบคำถามได้เก่ง แต่ follow-up queue ค้างโดยไม่มีใครรู้ ธุรกิจเสีย lead
หรือคุณมี coding agent ช่วยทีม dev แก้ระบบหลังบ้าน
ถ้า agent compact context แล้ว model alias ผิด จนรันต่อไม่ได้แต่ fail แบบไม่ชัด ทีมเสียเวลา debug
หรือคุณมี AI coworker ที่รับงานผ่าน Telegram แล้วมี subagent ไปอ่านไฟล์ สรุป แล้วส่งกลับ
ถ้า subagent ทำเสร็จแล้ว announce หาย main agent อาจคิดว่างานยังไม่เสร็จ หรือแย่กว่านั้นคือคนคิดว่า agent ไม่ทำงาน
ปัญหาแบบนี้ไม่ได้เกิดจาก model ไม่เก่งเสมอไปครับ
มันเกิดจาก reliability layer รอบตัว agent ยังไม่พร้อม
3) บทเรียนใหญ่: Agent ต้องมี “ระบบกันงานหาย”
AI Agent ที่ใช้จริงควรถูกมองเหมือนพนักงานคนหนึ่งที่ทำงานผ่านหลายระบบ
พนักงานที่ดีไม่ได้แค่ฉลาด แต่ต้องส่งต่องานเป็น, จดว่าอะไรทำแล้ว, ขออนุมัติถูกคน, แจ้งเมื่อทำไม่ได้, และมีหลักฐานให้ตรวจย้อนหลัง
AI Agent ก็เหมือนกันครับ
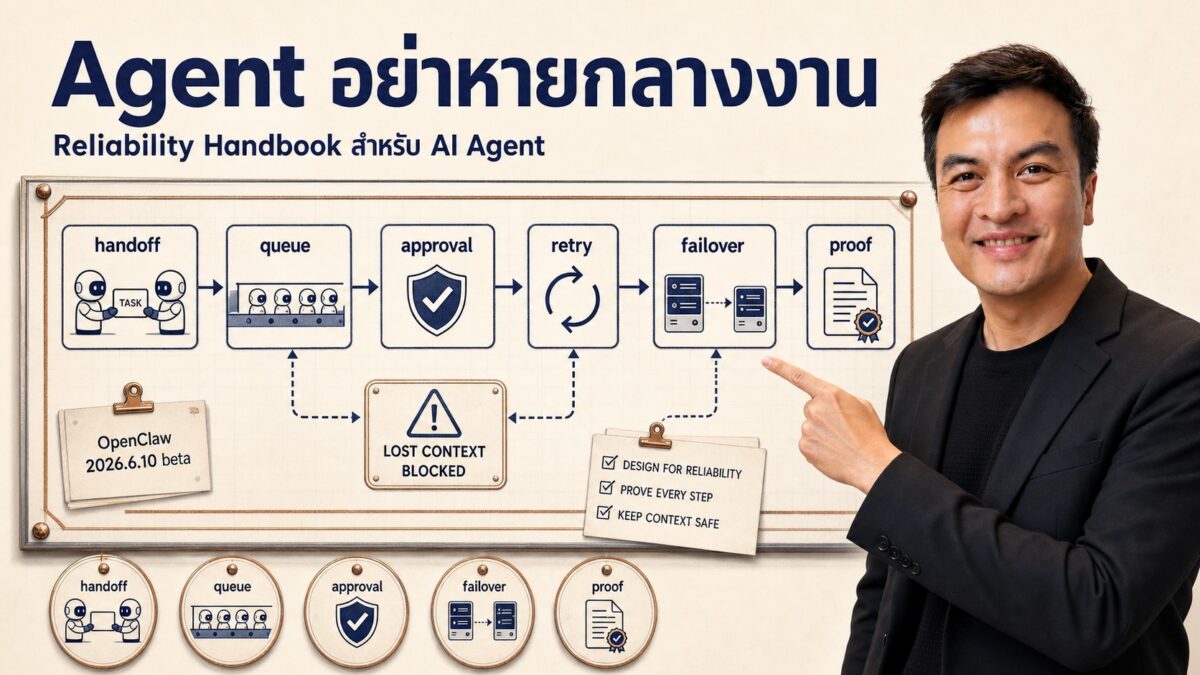
ถ้า agent ทำงานผ่าน chat, tools, files, cron, Slack, Telegram, GitHub, CRM หรือ MCP server เราต้องออกแบบ “Reliability Handbook” รอบตัวมัน
ไม่อย่างนั้นเราจะได้ agent ที่ดูเก่งตอน demo แต่หลุดง่ายตอนใช้จริง
4) จุดที่ควรจับตาจาก OpenClaw release นี้
ผมจะไม่ไล่ทุก PR เพราะจะกลายเป็น release-note translation แต่มี 5 pattern ที่ควรเอาไปใช้กับทุก agent stack
4.1 Handoff ต้องมี proof
PR #94349 แก้เรื่อง pending subagent completion announces โดย root cause คือสถานะอย่าง accepted, started, in_flight ถูกตีความไม่สม่ำเสมอ จน registry อาจ retry จน budget หมดและ abandon announce
แปลเป็นภาษางานจริงคือ subagent อาจส่งสัญญาณว่า “ผมส่งงานแล้ว” แต่ระบบฝั่งรับตีความว่า “ยังไม่ delivered” แล้วงานหายหรือวน retry
สำหรับ operator นี่คือคำถามสำคัญ:
- ทุก handoff มี receipt ไหม
- สถานะ
accepted,started,in_flight,delivered,failedแยกกันชัดไหม - ถ้า handoff อยู่สถานะ pending นานเกินไป ใครรู้
- ถ้า retry หมด budget แล้ว ระบบแจ้งคนหรือเงียบ
4.2 Queue ต้องตื่นเองเมื่อมีงานใหม่
PR #95039 แก้ dormant follow-up drain ที่อาจไม่ restart เมื่อ enqueue แข่งกับ completion ของ active reply run
ในภาษาธุรกิจ นี่คือปัญหา “งานเข้าแล้วแต่คนดูแลคิวหลับอยู่”
ถ้าคุณใช้ agent ทำ follow-up, customer support, task routing หรือ content pipeline queue drain สำคัญมาก เพราะงานอาจค้างแบบไม่มี error ใหญ่ให้เห็น
คำถามที่ควรมีใน SOP คือ:
- queue มี heartbeat หรือไม่
- ถ้ามีงานใหม่เข้าหลัง run จบ ระบบปลุก worker ใหม่ไหม
- มี dashboard หรือ log บอกงานค้างเกิน SLA ไหม
- มี manual drain command สำหรับกู้ไหม
4.3 Context และ transcript ต้องไม่หลอกเรา
Release นี้พูดถึง chat history transcript, media index alignment และ compaction model alias
เรื่องเหล่านี้ดูเล็ก แต่ agent ที่ทำงานจริงพึ่งพา transcript มากครับ
ถ้า transcript ว่างทั้งที่ควรมีข้อมูล agent จะจำบริบทผิด
ถ้า media URL หรือ content type สลับ index agent อาจอ่านไฟล์ผิดไฟล์
ถ้า compaction model alias resolve ผิด agent อาจพังตอน session ยาวโดยที่คนไม่เข้าใจว่าทำไม
นี่คือเหตุผลที่ agent workflow ต้องมี regression test สำหรับ session ยาวและ attachment หลายไฟล์ ไม่ใช่ test เฉพาะ prompt สั้น ๆ
4.4 Approval ต้อง route ถูกที่
Release note พูดถึง Codex approval context, SecretRefs, typed SDK approval/session helpers และ explicit cron delivery targets
ผมมองว่านี่คือแกนสำคัญของ agent governance
ถ้า agent จะทำ action ที่มีผลจริง เช่น ส่งข้อความ, รัน command, แตะ secret, แก้ code, เรียก API หรือทำงานตามเวลา มันต้องรู้ว่า approval ขอจากใคร ช่องทางไหน และ action นั้นผูกกับ session ไหน
approval ที่ดีไม่ใช่ปุ่ม “อนุญาต” แบบลอย ๆ ครับ
มันต้องมี context, scope, target, expiry และ audit trail
4.5 Failover ต้องไม่เงียบ
OpenClaw release นี้มีหลายจุดที่เกี่ยวกับ provider และ model behavior เช่น unsupported xAI multi-agent model refs, Zhipu GLM overload classification, Z.ai baseUrl fallback และ live-discovered thinking levels
บทเรียนคือเวลา model หรือ provider fail ระบบต้องบอกเหตุผลเป็นภาษาที่แก้ได้
ไม่ใช่เงียบ, fallback มั่ว, หรือยิงไปผิด endpoint แล้วคนคิดว่า agent โง่
สำหรับทีมที่ใช้หลาย provider นี่สำคัญมาก เพราะ agent ที่มี failover ดี จะช่วยให้ workflow รอดจาก outage หรือ rate limit ได้
แต่ failover ที่ไม่โปร่งใส อาจทำให้ผลลัพธ์เปลี่ยนคุณภาพโดยไม่มีใครรู้
Operator Kit: Agent Reliability Handbook
ใช้ checklist นี้ก่อนเอา AI Agent ไปแตะ workflow จริงครับ
A) Handoff checklist
- ทุก subagent หรือ tool call ต้องมี
task_idหรือ correlation ID - ทุก handoff ต้องมีสถานะอย่างน้อย
accepted,running,delivered,failed,timed_out - pending นานเกิน SLA ต้องแจ้งเตือน
- retry budget หมดต้องมี human-visible error
- completion message ต้องถูกผูกกับ session และ channel เดิม
B) Queue checklist
- queue มี heartbeat หรือ last-drain timestamp
- มี metric จำนวนงานรอ, งานค้างเกิน SLA, งาน retry, งาน failed
- ถ้า enqueue เกิดตอน worker เพิ่งจบ ระบบต้อง restart drain ได้
- มี manual replay หรือ requeue ที่ไม่ทำให้ duplicate action
- idempotency key ต้องมีสำหรับ action ที่กระทบลูกค้าหรือเงินจริง
C) Session and context checklist
- chat history ต้องไม่ว่างโดยไม่ตั้งใจ
- attachment หลายไฟล์ต้อง preserve index ระหว่าง path, URL และ media type
- compaction ต้องมี model alias validation
- session ยาวต้องมี regression test
- ถ้า context ถูก compact ต้องมี note ว่าอะไรถูกเก็บ อะไรถูกตัด
D) Approval checklist
- action เสี่ยงต้องมี human approval
- approval prompt ต้องบอก scope, target, data touched, tool, expiry และ rollback
- cron หรือ scheduled agent ต้องมี explicit delivery target
- secret access ต้องใช้ reference หรือ vault pattern ไม่ใช่ paste secret ลง prompt
- approval result ต้องถูกบันทึกใน audit log
E) Provider and failover checklist
- unsupported model ref ต้อง fail fast พร้อม error ที่อ่านออก
- overload, rate limit, auth error และ endpoint error ต้องแยกประเภท
- failover ต้อง log ว่าเปลี่ยนจาก model ไหนไป model ไหน
- งานที่ต้องการ quality คงที่ ต้องระบุ model policy ไม่ใช่ fallback อัตโนมัติทุกกรณี
- ถ้า fallback เกิดกับงานสำคัญ ต้องแจ้ง human หรือ mark output ว่า degraded
F) Channel delivery checklist
- Slack, Telegram, Discord, LINE หรือ email ต้องมี canonical sent thread หรือ message ID
- progress message, reasoning summary และ final output ต้องไม่หายหรือซ้ำ
- send error ต้อง structured พอให้ agent หรือ operator แก้ต่อได้
- media failure ต้องไม่ทำให้ text สำคัญหาย
- thread reply ต้องผูกกับ conversation เดิม ไม่ใช่หลุดไปช่องใหม่
6) Incident review template
ถ้า agent ทำงานหายกลางทาง ให้ review ด้วย 7 คำถามนี้
- งานเริ่มจาก trigger ไหน
- task ID หรือ correlation ID คืออะไร
- handoff ล่าสุดอยู่สถานะอะไร
- queue มีงานค้างหรือ drain หลับไหม
- context หรือ transcript ถูก compact หรือหายไหม
- approval ไปถึงคนและ channel ที่ถูกไหม
- provider หรือ tool fail แบบไหน และ failover เกิดหรือไม่
ถ้าตอบ 7 ข้อนี้ไม่ได้ แปลว่า agent workflow ยังไม่มี proof layer พอครับ
7) แล้วควรอัปเกรด OpenClaw beta นี้ไหม
ผมจะไม่สรุปว่า “ทุกคนควรอัปเกรดทันที” เพราะ source นี้เป็น prerelease beta
ถ้าใช้ OpenClaw อยู่แล้ว ควรอ่าน release note และทดสอบใน sandbox ก่อน โดยเฉพาะจุดที่เกี่ยวกับ channel delivery, cron, provider fallback และ session state
แต่ถึงไม่ได้ใช้ OpenClaw บทเรียนนี้ยังใช้ได้กับ agent stack อื่นครับ
เพราะ Claude Code, Codex, Hermes, MCP servers, custom Slack bot หรือ workflow agent ของทีมคุณ ล้วนเจอปัญหา reliability แบบเดียวกันได้
สรุป
ในความเห็นของผม OpenClaw release นี้มีคุณค่าตรงที่มันเตือนเราว่า AI Agent ที่ใช้งานจริงต้องมี operating system รอบตัว ไม่ใช่มีแค่โมเดล
Agent ที่ดีต้องส่งต่องานได้, ไม่ลืม context, ขออนุมัติถูกที่, retry อย่างมีขอบเขต, failover แบบโปร่งใส และมี proof ว่าอะไรเกิดขึ้น
ถ้าคุณกำลังเริ่มเอา AI Agent เข้า workflow ธุรกิจ อย่าเริ่มจากคำถามว่า “รุ่นไหนฉลาดสุด” อย่างเดียวครับ
ให้ถามเพิ่มว่า:
ถ้า agent หายกลางทาง เราจะรู้ไหม และกู้กลับอย่างไร?
คำตอบของคำถามนี้คือเส้นแบ่งระหว่าง AI demo กับ AI coworker ที่ไว้ใจได้จริง