สวัสดีครับเพื่อนๆ ชาว Data-Espresso! วันนี้เรามาพูดคุยกันเรื่องสุดฮอตในวงการ AI กันหน่อยดีกว่า นั่นก็คือการเปรียบเทียบระหว่าง Supervised Learning, LLM (Large Language Model), RAG (Retrieval-Augmented Generation) และ Fine-tuning ครับ แต่ละวิธีนี้มีจุดเด่นจุดด้อยยังไง? แล้วเราควรเลือกใช้แบบไหนดี? เรามาไขข้อข้องใจกันเลยครับ!
1️⃣ Supervised Learning: จากครูสู่ศิษย์
👉เริ่มกันที่ Supervised Learning กันก่อนเลยครับ นี่คือวิธีการสอน AI แบบดั้งเดิมที่เราคุ้นเคยกันดี เปรียบเสมือนครูที่คอยสอนนักเรียนทีละขั้นตอน โดยให้ข้อมูลที่มีคำตอบถูกต้องไว้แล้ว
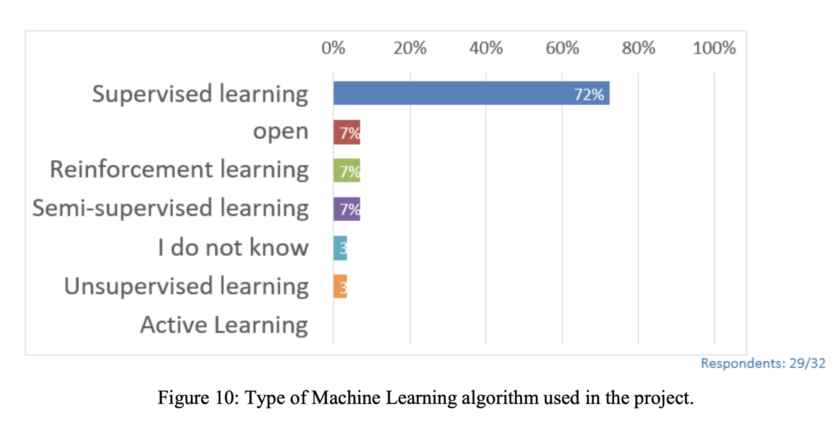
📈สถิติน่าสนใจ:
จากการสำรวจของ European Spatial Data Research ในปี 2021 พบว่า 72% ของโปรเจค AI ในองค์กรยังคงใช้ Supervised Learning เป็นหลัก ทำไมถึงเป็นเช่นนั้นล่ะครับ?
✅ ข้อดีของ Supervised Learning:
– แม่นยำสูง: เมื่อมีข้อมูลที่ถูกต้องมากพอ ความแม่นยำอาจสูงถึง 95-99% ในบางงาน
– ควบคุมได้: เราสามารถกำหนดทิศทางการเรียนรู้ได้อย่างชัดเจน
– เข้าใจง่าย: หลักการไม่ซับซ้อน ทำให้อธิบายและตรวจสอบได้ง่าย
⚠️ ข้อเสียของ Supervised Learning:
– ต้องการข้อมูลจำนวนมาก: บางครั้งต้องใช้ข้อมูลหลายแสนถึงหลายล้านตัวอย่าง
– เสียเวลาและค่าใช้จ่ายสูง: การเตรียมข้อมูลและติดฉลากใช้เวลาและทรัพยากรมาก
– ไม่ยืดหยุ่น: มักจะทำงานได้ดีเฉพาะในขอบเขตที่ถูกสอนเท่านั้น
💡 ความเห็นส่วนตัว: Supervised Learning ยังคงเป็นทางเลือกที่ดีสำหรับงานที่ต้องการความแม่นยำสูงและมีขอบเขตชัดเจน แต่อาจไม่เหมาะกับงานที่ต้องการความยืดหยุ่นสูงครับ
2️⃣ LLM: ยักษ์ใหญ่แห่งวงการ NLP
👉มาถึงขวัญใจมหาชนอย่าง LLM (Large Language Model) กันบ้างครับ นี่คือโมเดลภาษาขนาดใหญ่ที่ถูกฝึกฝนด้วยข้อมูลมหาศาล ทำให้สามารถเข้าใจและสร้างภาษามนุษย์ได้อย่างน่าทึ่ง
📈สถิติน่าสนใจ:
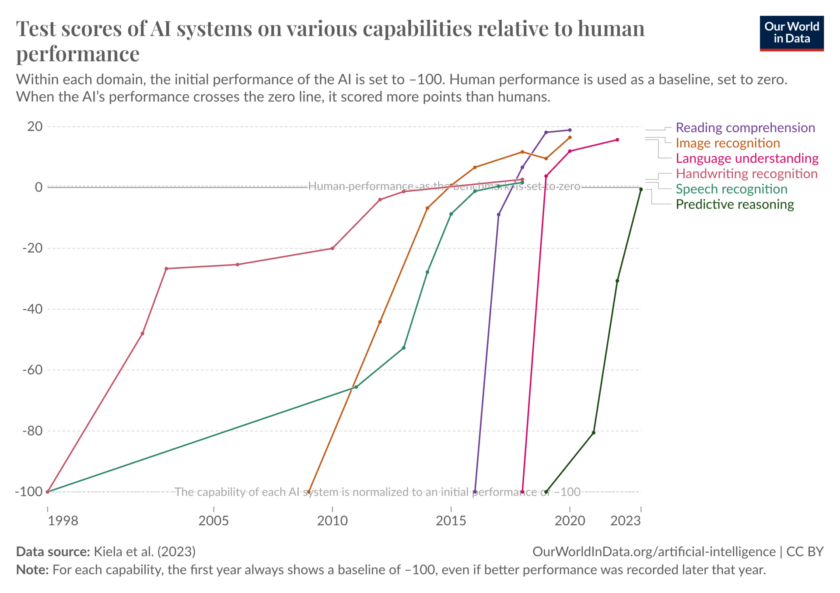
มีการคาดการณ์ถึงโมเดลของ OpenAI GPT-4 มีพารามิเตอร์มากถึง 1.76 ล้านล้านตัว! เทียบกับสมองมนุษย์ที่มีการเชื่อมต่อระหว่างเซลล์ประสาทประมาณ 100 ล้านล้านจุด คุณว่ามันน่าตื่นเต้นแค่ไหนครับ? ถ้าดูจากกราฟด้านล่างเราจะเห็นได้ว่าตอนนี้ AI ได้มีความสามารถแซงหน้ามนุษย์อย่างเราได้หลายอย่างแล้วนะครับเนี่ย 😱
✅ ข้อดีของ LLM:
– ความสามารถหลากหลาย: สามารถทำงานได้หลายอย่าง ตั้งแต่แปลภาษา เขียนโค้ด ไปจนถึงสร้างเนื้อหาสร้างสรรค์
– เข้าใจบริบท: สามารถเข้าใจความหมายแฝงและนัยยะต่างๆ ได้ดี
– ปรับตัวได้: สามารถทำงานกับข้อมูลที่ไม่เคยเห็นมาก่อนได้ดี
⚠️ ข้อเสียของ LLM:
– ใช้ทรัพยากรมาก: ต้องการพลังการประมวลผลและพลังงานมหาศาลในการ Train Model
– Black Box: ยากที่จะเข้าใจกระบวนการตัดสินใจภายใน
– Hallucination: อาจสร้างข้อมูลที่ผิดพลาดหรือไม่มีอยู่จริงได้
💡ความเห็นส่วนตัว: LLM เป็นเทคโนโลยีที่น่าตื่นเต้นมาก แต่ก็ต้องใช้อย่างระมัดระวัง โดยเฉพาะในงานที่ต้องการความถูกต้องสูงครับ
3️⃣ RAG: ผู้ช่วยที่ช่วยให้ LLM ฉลาดขึ้น
👉 RAG หรือ Retrieval-Augmented Generation เป็นเทคนิคที่นำเอาความสามารถของ LLM มาผสมผสานกับระบบค้นคืนข้อมูล ทำให้ได้ผลลัพธ์ที่แม่นยำและน่าเชื่อถือมากขึ้น
📈สถิติน่าสนใจ:
– แม้จะไม่มีตัวเลขที่ชัดเจน แต่ตามรายงานของ Relevance AI การใช้ RAG สามารถลดอัตราการเกิด Hallucination จากประมาณ 16% เหลือเพียง 4%
– อัตราการเกิด Hallucination ของ LLM ที่ดีที่สุดอย่าง GPT-4 Turbo อยู่ที่ประมาณ 2.5% ในขณะที่ LLM อื่นๆ อาจมีอัตราสูงถึง 22.4% (ที่มา: How RAGs Help Mitigate LLM Hallucinations: 5 Use Cases | Radicalbit)
✅ ข้อดีของ RAG:
– ข้อมูลทันสมัย: สามารถดึงข้อมูลล่าสุดมาใช้ได้ตลอดเวลา
– ลดการ Hallucinate: มีแหล่งข้อมูลอ้างอิงที่ชัดเจน
– ยืดหยุ่นสูง: สามารถปรับเปลี่ยนแหล่งข้อมูลได้ตามต้องการ
⚠️ ข้อเสียของ RAG:
– ซับซ้อนกว่า: ต้องจัดการทั้งส่วน LLM และระบบค้นหาข้อมูล
– ขึ้นกับคุณภาพข้อมูล: หากข้อมูลที่ใช้ไม่ดี ผลลัพธ์ก็อาจไม่ดีตามไปด้วย
– อาจช้ากว่า: ต้องใช้เวลาในการค้นหาและประมวลผลข้อมูลเพิ่มเติม
💡ความเห็นส่วนตัว: RAG เป็นทางเลือกที่น่าสนใจมากสำหรับองค์กรที่ต้องการใช้ LLM แต่ยังกังวลเรื่องความถูกต้องของข้อมูลครับ
4️⃣ Fine-tuning: ปรับแต่งให้เข้ากับความต้องการ
👉 Fine-tuning เป็นเทคนิคการปรับแต่ง LLM ที่มีอยู่แล้วให้เชี่ยวชาญในงานเฉพาะทางมากขึ้น โดยใช้ข้อมูลเฉพาะทางในการฝึกฝนเพิ่มเติม
📈สถิติน่าสนใจ:
ตามรายงานของ Hugging Face การ Fine-tune LLM ด้วยข้อมูลเฉพาะทางสามารถเพิ่มประสิทธิภาพในงานเฉพาะทางได้อย่างมีนัยสำคัญ โดยพบว่าโมเดลที่ผ่านการ Fine-tune ด้วย LoRA แบบ 4-bit สามารถทำคะแนนได้ดีกว่าโมเดลพื้นฐานถึง 34 คะแนนโดยเฉลี่ย และยังทำคะแนนได้ดีกว่า GPT-4 ถึง 10 คะแนนโดยเฉลี่ย (ที่มา)
✅ ข้อดีของ Fine-tuning:
– เชี่ยวชาญเฉพาะทาง: สามารถปรับแต่งให้เก่งในงานเฉพาะได้
– ใช้ข้อมูลน้อยกว่า: ไม่จำเป็นต้องฝึกฝน LLM ใหม่ทั้งหมด
– รวดเร็วกว่า: ใช้เวลาในการฝึกฝนน้อยกว่าการสร้าง LLM ใหม่
⚠️ ข้อเสียของ Fine-tuning:
– อาจสูญเสียความสามารถทั่วไป: ถ้า Fine-tune มากเกินไปอาจทำให้โมเดลทำงานอื่นๆ ได้แย่ลง
– ต้องระวังเรื่อง Overfitting: อาจเกิดการจำข้อมูลฝึกฝนมากเกินไป
– ยังต้องการทรัพยากรค่อนข้างมาก: แม้จะน้อยกว่าการสร้าง LLM ใหม่ แต่ก็ยังต้องใช้ทรัพยากรไม่น้อย
💡ความเห็นส่วนตัว: Fine-tuning เป็นตัวเลือกที่ดีสำหรับองค์กรที่ต้องการใช้ LLM ในงานเฉพาะทาง แต่ไม่มีทรัพยากรมากพอที่จะสร้าง LLM ขึ้นมาใหม่เองครับ
5️⃣ เปรียบเทียบทั้ง 4 วิธี: ใครเหมาะกับอะไร?
👉 มาถึงตอนนี้ เราก็ได้รู้จักทั้ง 4 วิธีกันแล้ว แต่คำถามสำคัญคือ แต่ละวิธีเหมาะกับงานแบบไหน และใครควรเลือกใช้วิธีไหนดีล่ะครับ? มาดูการเปรียบเทียบกันแบบละเอียดกันเลยครับ
📈 สถิติน่าสนใจ:
จากการสำรวจของ PwC ระบุว่า 54% ของบริษัทที่สำรวจได้นำ Generative AI ไปใช้ในบางส่วนของธุรกิจแล้ว แม้จะยังไม่มีตัวเลขที่แน่ชัด แต่ตอนนี้ มีการใช้งานร่วมกันระหว่าง Supervised Learning และ LLM ในหลายองค์กรแล้วครับ 2024 AI Business Predictions: PwC
⚖️ เปรียบเทียบในหัวข้อสำคัญ:
1. ความแม่นยำ:
– Supervised Learning: สูงมาก (90-99%) ในงานที่มีขอบเขตชัดเจน
– LLM: ปานกลางถึงสูง (70-90%) ขึ้นอยู่กับความซับซ้อนของงาน
– RAG: สูง (85-95%) โดยเฉพาะในงานที่ต้องการข้อมูลเฉพาะเจาะจง
– Fine-tuning: สูงมาก (90-98%) ในงานเฉพาะทางที่ได้รับการปรับแต่ง
2. ความยืดหยุ่น:
– Supervised Learning: ต่ำ (ทำได้ดีเฉพาะงานที่ถูกฝึกมา)
– LLM: สูงมาก (สามารถปรับตัวได้กับงานหลากหลาย)
– RAG: สูง (ยืดหยุ่นตามข้อมูลที่ใช้ในการค้นคืน)
– Fine-tuning: ปานกลาง (ยืดหยุ่นในขอบเขตที่ได้รับการปรับแต่ง)
3. ทรัพยากรที่ต้องใช้:
– Supervised Learning: ปานกลาง (ต้องการข้อมูลมาก แต่ประมวลผลไม่ซับซ้อน)
– LLM: สูงมาก (ต้องการพลังการประมวลผลและพลังงานมหาศาล)
– RAG: สูง (ต้องจัดการทั้ง LLM และระบบค้นคืนข้อมูล)
– Fine-tuning: สูง (น้อยกว่า LLM แต่ยังต้องใช้ทรัพยากรมาก)
4. ความเร็วในการพัฒนา:
– Supervised Learning: ช้า ต้องเตรียมข้อมูล, การทำ Label และฝึกฝนนาน
– LLM: เร็ว (สามารถใช้งานได้ทันทีหลังการฝึกฝน)
– RAG: ปานกลาง (ต้องเตรียมระบบค้นคืนข้อมูล)
– Fine-tuning: เร็วปานกลาง (เร็วกว่าสร้าง LLM ใหม่ แต่ช้ากว่าใช้ LLM ทั่วไป)
💡ความเห็นส่วนตัว: แต่ละวิธีมีจุดเด่นจุดด้อยต่างกัน การเลือกใช้ขึ้นอยู่กับลักษณะงาน ทรัพยากรที่มี และความต้องการเฉพาะขององค์กรครับ บางครั้งการผสมผสานหลายวิธีเข้าด้วยกันอาจให้ผลลัพธ์ที่ดีที่สุด
6. มาดูตัวอย่างการใช้งานกันบ้างดีกว่าครับว่าเราสามารถเลือกใช้วิธีไหนได้บ้าง
✏️ บริษัท A (E-commerce ขนาดใหญ่):
– เลือกใช้: Supervised Learning + LLM
– เหตุผล: ใช้ Supervised Learning ในการวิเคราะห์พฤติกรรมการซื้อและแนะนำสินค้า ส่วน LLM ใช้ในการสร้างคำบรรยายสินค้าและตอบคำถามลูกค้า
✏️ บริษัท B (สตาร์ทอัพด้าน Legal Tech):
– เลือกใช้: RAG
– เหตุผล: ต้องการความแม่นยำสูงในการค้นหาและอ้างอิงข้อกฎหมาย จึงใช้ RAG เพื่อให้ LLM สามารถดึงข้อมูลกฎหมายล่าสุดมาใช้ได้
✏️ บริษัท C (โรงพยาบาลชั้นนำ):
– เลือกใช้: Fine-tuned LLM
– เหตุผล: ต้องการ AI ที่เข้าใจศัพท์แพทย์และสามารถวิเคราะห์ข้อมูลทางการแพทย์ได้อย่างแม่นยำ จึงเลือก Fine-tune LLM ด้วยข้อมูลทางการแพทย์โดยเฉพาะ
💡 ความเห็นส่วนตัว: แต่ละอุตสาหกรรมมีความต้องการที่แตกต่างกัน การเลือกใช้เทคโนโลยี AI ที่เหมาะสมจึงเป็นกุญแจสำคัญสู่ความสำเร็จครับ
7️⃣ แนวโน้มในอนาคต: อะไรจะมาแรงต่อไป?
👉 เทคโนโลยี AI พัฒนาไปอย่างรวดเร็วมากครับ แล้วอะไรจะเป็นเทรนด์ต่อไปในอนาคตล่ะ? มาดูกันเลย!
1. Hybrid Models: การผสมผสานระหว่าง Supervised Learning และ LLM จะเพิ่มมากขึ้น เพื่อให้ได้ทั้งความแม่นยำและความยืดหยุ่น
2. Ethical AI: การพัฒนา AI ที่คำนึงถึงจริยธรรมและความเป็นธรรมจะเป็นประเด็นสำคัญมากขึ้น
3. Explainable AI: เทคโนโลยีที่ช่วยให้เข้าใจการตัดสินใจของ AI ได้ดีขึ้นจะได้รับความสนใจมากขึ้น
4. Edge AI: การนำ AI ไปใช้งานบนอุปกรณ์ปลายทางโดยตรง เพื่อลดการส่งข้อมูลกลับไปกลับมา
5. Multimodal AI: AI ที่สามารถทำงานกับข้อมูลหลายรูปแบบ (ข้อความ, ภาพ, เสียง) พร้อมกันจะพัฒนามากขึ้น
💡ความเห็นส่วนตัว: ผมเชื่อว่า Hybrid Models และ Ethical AI จะเป็นเทรนด์ที่น่าจับตามองมากที่สุดในอีก 2-3 ปีข้างหน้าครับ
☕ สรุป: เลือกให้เหมาะ ใช้ให้เป็น
เราได้เรียนรู้กันมาเยอะเลยนะครับ มาสรุปประเด็นสำคัญกันอีกทีดีกว่า:
1. Supervised Learning ยังคงเป็นตัวเลือกที่ดีสำหรับงานที่ต้องการความแม่นยำสูงและมีขอบเขตชัดเจน
2. LLM เหมาะกับงานที่ต้องการความยืดหยุ่นและความสามารถหลากหลาย
3. RAG ช่วยเพิ่มความแม่นยำให้กับ LLM โดยเฉพาะในงานที่ต้องการข้อมูลเฉพาะเจาะจง
4. Fine-tuning เหมาะสำหรับการปรับแต่ง LLM ให้เชี่ยวชาญในงานเฉพาะทาง
สุดท้ายนี้ การเลือกใช้เทคโนโลยี AI ไม่มีสูตรสำเร็จตายตัวครับ ต้องพิจารณาจากความต้องการเฉพาะ ทรัพยากรที่มี และเป้าหมายขององค์กร บางครั้งการผสมผสานหลายวิธีเข้าด้วยกันอาจให้ผลลัพธ์ที่ดีที่สุด
คุณล่ะครับ คิดว่าวิธีไหนเหมาะกับองค์กรของคุณมากที่สุด? ลองนำไปพิจารณาดูนะครับ และอย่าลืมว่า AI เป็นเพียงเครื่องมือ การใช้งานอย่างมีวิจารณญาณและมีจริยธรรมเป็นสิ่งสำคัญที่สุดครับ!
#AI #MachineLearning #SupervisedLearning #LLM #RAG #FineTuning #FutureOfAI #AITrends