
Google เปิด OKF: บริบทบริษัทที่ AI Agent อ่านได้ ไม่ต้องเดา
ถ้าคุณเคยให้ AI วิเคราะห์ข้อมูลบริษัท แล้วคำตอบดูมั่นใจแต่ผิดบริบท คุณอาจไม่ได้เจอปัญหาเรื่องโมเดลอย่างเดียวครับ
คุณอาจเจอปัญหาเรื่อง บริบทของบริษัทไม่มีที่อยู่ชัดเจน
Google Cloud เปิด Open Knowledge Format หรือ OKF เป็น spec แบบเปิดสำหรับจัดความรู้ให้มนุษย์และ AI Agent อ่านร่วมกันได้
ฟังดูเหมือนเรื่อง data catalog หรือ documentation ธรรมดา แต่ผมว่าเรื่องนี้สำคัญกว่านั้น
เพราะถ้า AI Agent จะเริ่มทำงานจริงในบริษัท ไม่ว่าจะตอบคำถาม วิเคราะห์ data เขียน report หรือเรียก workflow มันต้องรู้ก่อนว่า “ความจริงของบริษัท” อยู่ตรงไหน
1) ปัญหาจริงไม่ใช่ AI ไม่เก่ง แต่คือ context กระจัดกระจาย
ในบริษัทจริง ความรู้ไม่ได้อยู่ในที่เดียว
บางอย่างอยู่ใน dashboard บางอย่างอยู่ใน CRM บางอย่างอยู่ใน spreadsheet บางอย่างอยู่ใน Notion บางอย่างอยู่ใน code comment บางอย่างอยู่ในหัวของพนักงาน senior คนหนึ่ง
ลองถามคำถามง่าย ๆ:
“เดือนนี้ลูกค้า active เพิ่มขึ้นไหม”
คำว่า active อาจหมายถึง login ภายใน 30 วัน หรือซื้อซ้ำภายใน 90 วัน หรือมี conversation กับทีม sales หรือจ่ายเงินแล้วแต่ยังไม่ได้เริ่มใช้งาน
สำหรับคนในทีม บางคนอาจรู้โดยประสบการณ์ แต่ AI Agent ไม่รู้ครับ
ถ้าเราไม่เขียน context นี้ให้มันอ่าน มันก็จะ assemble คำตอบจากเศษข้อมูลที่หาเจอ แล้วเติมช่องว่างเอง
นี่คือจุดที่ OKF เข้ามาน่าสนใจ
2) OKF คืออะไรแบบไม่ technical เกินไป
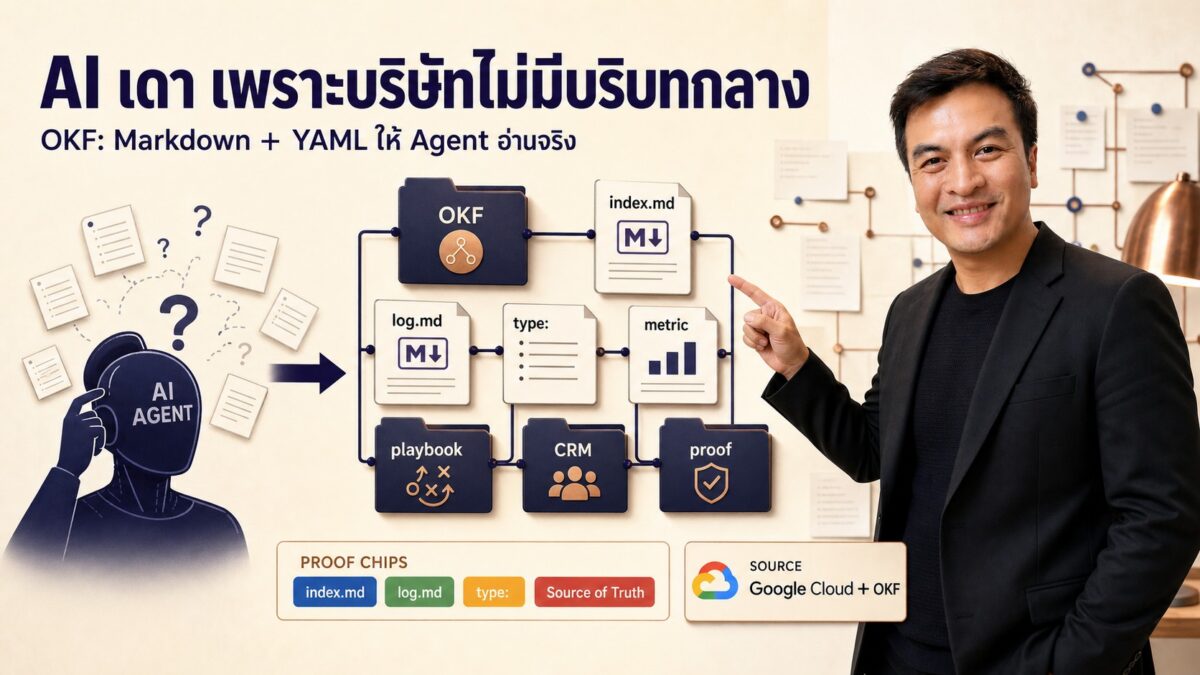
OKF หรือ Open Knowledge Format คือรูปแบบการเก็บความรู้เป็น folder ของ markdown files พร้อม YAML frontmatter
หนึ่งไฟล์แทนหนึ่ง concept เช่น:
- table หนึ่งตัว
- metric หนึ่งตัว
- playbook หนึ่งชุด
- runbook หนึ่งเรื่อง
- API endpoint หนึ่งตัว
- policy หนึ่งหน้า
- source document หนึ่งชิ้น
ใน OKF v0.1 สิ่งที่ทุก concept ต้องมีจริง ๆ มีแค่ field เดียวคือ type
ส่วน field ที่แนะนำ เช่น title, description, resource, tags, timestamp
ตัวอย่างแบบย่อ:
---
type: Metric
title: Monthly Revenue
description: รายได้ที่รับรู้ตาม invoice ที่ paid แล้วในเดือนนั้น
resource: https://example.com/dashboard/revenue
tags: [finance, revenue]
timestamp: 2026-06-22T07:00:00+07:00
---
# Definition
Monthly Revenue นับเฉพาะ invoice ที่ paid แล้ว ไม่รวม quotation และ trial account
# Examples
ใช้สำหรับ monthly management report และ board update
# Citations
[1] Finance policy v3จุดสำคัญคือไฟล์แบบนี้อ่านได้ทั้งคนและ AI
คนเปิดใน GitHub, Obsidian, VS Code หรือเว็บธรรมดาก็เข้าใจ AI Agent โหลดเข้า context ก็เข้าใจ และทีมสามารถ review ผ่าน git diff ได้เหมือน code
3) “Format, not platform” คือประโยคที่ควรจำ
ใน Google Cloud Blog มีประเด็นที่ผมชอบมาก
เขาบอกว่าปัญหานี้ต้องการ format ไม่ใช่ service ใหม่อีกตัว
เพราะถ้าทุก vendor มี catalog, schema, SDK และ API ของตัวเอง ความรู้ก็ยังติดอยู่ใน platform เดิม
แต่ถ้าความรู้ถูกเก็บเป็น folder, markdown, frontmatter และ link ปกติ มันย้ายได้ง่ายกว่า
จะอยู่ใน git repo ก็ได้ จะ sync เข้า Knowledge Catalog ก็ได้ จะเปิดใน Obsidian ก็ได้ จะให้ agent อ่านตรง ๆ ก็ได้ จะทำ visualizer เป็น graph ก็ได้
ตรงนี้คือเหตุผลที่ OKF น่าสนใจ ไม่ใช่เพราะมันซับซ้อน แต่เพราะมันตั้งใจไม่ซับซ้อน
4) ต่างจาก RAG ทั่วไปยังไง
หลายคนอาจถามว่า “แล้วนี่ไม่ใช่ knowledge base หรือ RAG เหรอ”
คล้ายครับ แต่ไม่เหมือน
RAG ทั่วไปมักเริ่มจากเอาเอกสารไป chunk, embed แล้วให้โมเดลค้นตอนตอบคำถาม
ปัญหาคือ chunk ไม่ได้แปลว่ามีความหมายทางธุรกิจเสมอไป
ถ้าเอกสารพูดถึง monthly revenue หลายหน้า AI อาจค้นเจอหลาย chunk แต่ยังไม่รู้ว่า definition ไหน current, query ไหน trusted, owner คือใคร, และควรใช้กรณีไหน
OKF มองคนละมุม
มันบอกว่าให้เราจัดความรู้เป็น concept ที่ curate แล้ว
ไม่ใช่แค่ “ข้อความที่ค้นได้” แต่เป็น “ความรู้ที่มีชื่อ มีประเภท มีเจ้าของ มีแหล่งอ้างอิง และเชื่อมกับ concept อื่น”
ถ้า RAG คือการค้นกองเอกสาร OKF คือการจัดห้องสมุดให้มีบัตรรายการ ทางเดิน และป้ายบอกว่าเล่มไหนควรใช้ตอนไหน
5) Knowledge Catalog คือ layer ที่อยู่เหนือ format
ต้องแยกสองเรื่องนี้ให้ชัดครับ
OKF คือ format
ส่วน Google Cloud Knowledge Catalog คือ product/platform ที่ช่วย aggregate, enrich, search, govern และ serve context ให้ agent
บน product page ของ Knowledge Catalog เขาวางตำแหน่งชัดว่าเป็น always-on context and governance สำหรับ agents มี metadata harvesting, enrichment, semantic search, Context APIs, MCP tools, governance, lineage, data quality และ permission-aware retrieval
แปลแบบง่าย ๆ:
- OKF = ภาษากลางของไฟล์ความรู้
- Knowledge Catalog = ระบบจัดเก็บ ค้นหา คุมสิทธิ์ และเสิร์ฟ context ให้ agent
ธุรกิจไม่ควรเข้าใจผิดว่าแค่ทำ markdown file แล้ว governance จบ
ไฟล์ format ช่วยให้ความรู้ portable และ review ได้ แต่เรื่อง permission, retrieval quality, logging, approval, eval และ access control ยังต้องมีระบบรองรับ
6) ทำไมเรื่องนี้เกี่ยวกับธุรกิจไทย
ผมคิดว่าธุรกิจไทยจำนวนมากยังติดอยู่ที่คำถามว่า “จะใช้ AI tool ตัวไหนดี”
แต่คำถามที่ควรถามก่อนคือ:
ถ้า AI ต้องทำงานแทนทีมบางส่วน มันจะอ่านความจริงของบริษัทจากไหน
ตัวอย่างเช่น CustomerOS, LINE OA, CRM, sales report, accounting sheet, course platform, helpdesk, workflow automation
ถ้าแต่ละระบบมีคำจำกัดความคนละแบบ AI จะตอบลูกค้าหรือสรุปงานผิดได้ง่ายมาก
AI อาจบอกว่า lead คนนี้ hot ทั้งที่จริงยังไม่มี consent AI อาจคิดว่าลูกค้ารายนี้ซื้อแล้ว ทั้งที่เป็น quotation AI อาจสรุปรายได้จากยอด invoice issued ทั้งที่ทีม finance ใช้ paid invoice AI อาจ trigger workflow ผิด เพราะชื่อ workflow อ่านแล้วดูคล้ายกัน
นี่ไม่ใช่ปัญหา prompt ครับ
นี่คือปัญหา source of truth
Operator Kit: Agent Context Bundle starter template
ถ้าจะเริ่มแบบไม่ใหญ่เกินไป ผมแนะนำให้ทำ Agent Context Bundle เล็ก ๆ ก่อน 1 ชุด
เป้าหมายไม่ใช่ทำ enterprise catalog ให้เสร็จในสัปดาห์เดียว
เป้าหมายคือทำให้ AI อ่านบริบทของ workflow หนึ่งได้ถูกกว่าการเดา
โครงสร้างเริ่มต้น
agent-context/
├── index.md
├── log.md
├── metrics/
│ ├── index.md
│ └── monthly_revenue.md
├── systems/
│ └── crm.md
├── playbooks/
│ └── lead-follow-up.md
├── tables/
│ └── customers.md
└── references/
└── sales-policy.mdไฟล์ที่ 1: index.md
ใช้เป็นแผนที่ให้คนและ AI เห็นว่ามีอะไรใน bundle นี้
ควรมี:
- workflow นี้เกี่ยวกับอะไร
- folder แต่ละชุดเก็บอะไร
- concept ไหนควรอ่านก่อน
- concept ไหนห้ามใช้เดี่ยว ๆ โดยไม่อ่าน policy
ไฟล์ที่ 2: log.md
ใช้บันทึกการเปลี่ยนแปลงแบบอ่านง่าย
ตัวอย่าง:
# Update Log
## 2026-06-22
- Update: เปลี่ยนนิยาม monthly revenue ให้ใช้ paid invoice เท่านั้น
- Creation: เพิ่ม lead follow-up playbook สำหรับทีม salesไฟล์ที่ 3: metrics/monthly_revenue.md
ตอบคำถามว่า metric นี้คืออะไร และไม่ใช่อะไร
ควรมี:
- definition
- owner
- source dashboard/query
- ตัวอย่างการใช้
- สิ่งที่ห้ามนับรวม
- citation ไปยัง policy หรือ report เดิม
ไฟล์ที่ 4: systems/crm.md
อธิบายระบบ CRM ให้ agent เข้าใจแบบ business language
ควรมี:
- CRM ใช้ทำอะไร
- field สำคัญ เช่น status, owner, consent, last_contact_at
- field ไหนเป็น source of truth
- field ไหนเป็น helper เท่านั้น
- ใคร approve การเปลี่ยนข้อมูลลูกค้า
ไฟล์ที่ 5: playbooks/lead-follow-up.md
บอกขั้นตอนทำงาน ไม่ใช่แค่นโยบายกว้าง ๆ
ควรตอบ:
- trigger คืออะไร
- input ต้องมีอะไร
- output หน้าตาเป็นอย่างไร
- เมื่อไหร่ต้องให้คน approve
- เมื่อไหร่ห้ามส่งข้อความลูกค้า
- proof หลังทำงานคืออะไร
ไฟล์ที่ 6: tables/customers.md
ถ้า workflow แตะข้อมูลลูกค้า ต้องอธิบาย table หรือ collection ที่เกี่ยวข้อง
ไม่ต้องใส่ข้อมูลลูกค้าจริง
ใส่ schema, ความหมายของ column, owner, data sensitivity และ query ตัวอย่างพอ
ไฟล์ที่ 7: references/sales-policy.md
เก็บ policy หรือเอกสารอ้างอิงที่ agent ควรอ่านก่อนทำงานเสี่ยง
เช่น:
- discount policy
- refund policy
- customer message policy
- consent policy
- escalation rule
Checklist ก่อนให้ AI ใช้ bundle นี้
- [ ] ทุก concept มี
type - [ ] ทุกไฟล์มี description ที่คนอ่านเข้าใจ
- [ ] metric สำคัญมี source of truth ชัด
- [ ] playbook ระบุ trigger, input, output, approval และ proof
- [ ] ไม่มี secret, token, password หรือข้อมูลลูกค้าจริงในไฟล์
- [ ] มี
log.mdสำหรับการเปลี่ยนแปลง - [ ] ให้ agent อ่านได้ แต่ให้แก้ผ่าน pull request หรือ review ก่อนเท่านั้น
7) 7-day pilot สำหรับทีมที่อยากลอง
ถ้าผมต้องเริ่มในบริษัทหนึ่ง ผมจะไม่เริ่มจากทุกระบบพร้อมกัน
ผมจะเลือก workflow เดียวก่อน เช่น lead follow-up, weekly sales report หรือ support escalation
Day 1: เลือก workflow เดียว
เลือกงานที่ทีมทำซ้ำ เห็นผลชัด และยังไม่แตะเงินหรือข้อมูลเสี่ยงมาก
Day 2: เขียน index.md และ log.md
ทำแผนที่และบันทึกการเปลี่ยนแปลงก่อน อย่าเริ่มจากไฟล์เยอะ
Day 3: เขียน metric หรือ system concept 1-2 ไฟล์
เน้นนิยามที่ทีมเถียงกันบ่อย เช่น lead status, revenue, active user, paid customer
Day 4: เขียน playbook หนึ่งไฟล์
ระบุ trigger, input, output, approval, forbidden action และ proof
Day 5: ให้ AI อ่าน bundle แล้วสรุปกลับ
ถาม AI ว่า workflow นี้ทำอะไร, metric หมายถึงอะไร, อะไรห้ามทำ
ถ้าตอบผิด ให้แก้ไฟล์ก่อน ไม่ใช่แก้ prompt ยาว ๆ
Day 6: ให้ AI ทำงานแบบ read-only
ให้มันสรุป report, ตรวจ inconsistency, draft follow-up หรือหา missing field
ยังไม่ให้แก้ข้อมูลจริง
Day 7: review ด้วยทีมจริง
ดูว่า AI ตอบถูกขึ้นไหม ทีมเข้าใจไฟล์ไหม และสิ่งที่เขียนช่วยลดคำถามซ้ำได้จริงหรือเปล่า
ถ้า 7 วันแล้วยังไม่มีประโยชน์ แปลว่า bundle ยังไม่ชัดพอหรือ workflow ที่เลือกยังไม่เหมาะ
8) ข้อควรระวัง: format ไม่ใช่ governance ทั้งหมด
ผมชอบ OKF เพราะมันเรียบง่ายและ practical
แต่ต้องไม่เข้าใจผิดว่า format เดียวจบทุกอย่าง
สิ่งที่ยังต้องออกแบบเพิ่มคือ:
- ใครอ่านไฟล์ไหนได้
- agent ตัวไหนเข้าถึง concept ไหนได้
- ถ้า agent แก้ไฟล์ ต้อง review อย่างไร
- retrieval จะเลือก concept ถูกไหม
- มี eval วัดไหมว่า agent ใช้ context ถูกจริง
- ถ้า context ผิด ใครแก้และบันทึกตรงไหน
- งานเสี่ยงต้องมี human approval ก่อนหรือไม่
พูดง่าย ๆ:
OKF ช่วยทำให้ความรู้เป็นของที่จับต้องได้ แต่ production AI ยังต้องมี permission, retrieval, approval และ proof อยู่ดี
9) ภาพใหญ่: บริษัทต้องเริ่มเขียนให้ AI อ่าน
เมื่อก่อนเราเขียนเอกสารให้คนอ่าน
ยุคต่อไปเราต้องเขียนเอกสารให้คนและ AI อ่านร่วมกัน
ไม่ใช่เขียนแบบโยน text ยาว ๆ เข้า knowledge base แล้วหวังว่า AI จะเข้าใจเอง
แต่เขียนเป็น concept ที่มีชื่อ มี type มี source มี link มีตัวอย่าง มีข้อห้าม และมี log
นี่คือการเปลี่ยนจาก documentation เป็น operating context
เอกสารไม่ได้มีไว้ให้คนเปิดอ่านเวลาไม่รู้
เอกสารกลายเป็นสิ่งที่ AI Agent ใช้ก่อนทำงาน
สรุป
ในความเห็นของผม OKF เป็นสัญญาณที่ดีมาก เพราะมันบอกตรง ๆ ว่าโลกของ AI Agent ไม่ได้ต้องการแค่โมเดลที่ฉลาดขึ้น
มันต้องการบริบทที่จัดรูปแล้ว ตรวจสอบได้ และย้ายข้ามเครื่องมือได้
สำหรับธุรกิจไทย ผมจะไม่เริ่มจากการทำ catalog ใหญ่ทั้งองค์กรทันที
ผมจะเริ่มจาก workflow หนึ่ง
ทำ Agent Context Bundle เล็ก ๆ
เขียน metric, system, playbook และ policy ให้คนอ่านเข้าใจ
แล้วให้ AI อ่านเพื่อช่วยงาน read-only ก่อน
ถ้ามันตอบถูกขึ้น ทีมใช้ไฟล์จริง และ review ได้ผ่าน git หรือ workflow ที่ชัดเจน ค่อยขยายต่อ
สุดท้าย AI Agent ที่ดีไม่ใช่แค่ตัวที่ต่อ tool ได้เยอะที่สุดครับ
แต่คือตัวที่รู้ว่าเวลาจะใช้ tool มันควรอ่านบริบทไหนก่อน และต้องเอา proof อะไรกลับมาให้คนตรวจ