

สมัยนี้ข้อมูลขนาดใหญ่ (Big Data) ถือเป็นสิ่งที่ไม่มีใครปฏิเสธได้ เพราะข้อมูลขนาดใหญ่มีส่วนสำคัญในการวางแผนและการตัดสินใจภายในองค์กร และเพื่อให้สามารถจัดการกับข้อมูลขนาดใหญ่ได้ดีขึ้น หนึ่งในวิธีการที่มีประสิทธิภาพคือการสร้างทีม Big Data ที่มีความสามารถและมีทักษะที่ตรงกับความต้องการขององค์กร

คุณต้องเริ่มต้นด้วยการเข้าใจว่าองค์กรของคุณต้องการอะไรจากทีม Big Data คุณต้องการให้ทีมนี้ช่วยแก้ปัญหาอะไรบ้าง ที่สำคัญคือคุณต้องการที่จะใช้ข้อมูลขนาดใหญ่ในการทำอะไร การรู้คำตอบสำหรับคำถามเหล่านี้จะช่วยให้คุณสามารถหาคนที่มีทักษะและประสบการณ์ที่เหมาะสมกับทีม Big Data ของคุณ
การสร้างทีม Big Data ไม่ใช่เพียงแค่เรื่องของการหาคนที่มีทักษะทางเทคนิค คุณต้องการทีมที่มีความสามารถในการสื่อสารที่ดี มีความคิดสร้างสรรค์และสามารถคิดอย่างลึกซึ้ง เพราะนั่นคือสิ่งที่จะช่วยให้ทีมของคุณสามารถจัดการกับความท้าทายและโอกาสที่มากับข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพ
คุณยังต้องการมองหาผู้มีประสบการณ์ในการทำงานร่วมกับเทคโนโลยี Big Data ที่สำคัญ เช่น Hadoop, Spark, NoSQL, และเครื่องมือที่สำคัญอื่นๆ เช่น Tableau และ Power BI สำหรับการวิเคราะห์ข้อมูล
ทั้งหมดนี้เพื่อแน่ใจว่าคุณสร้างทีม Big Data ที่เหมาะสมและมีประสิทธิภาพ ทีมที่สามารถจัดการกับข้อมูลขนาดใหญ่ในระดับที่คุณต้องการ และที่สุดท้ายนี้คือการให้การสนับสนุนและทรัพยากรที่เพียงพอให้ทีมของคุณทำงานได้ด้วยความสามารถเต็มที่
การสร้างทีม Big Data เป็นขั้นตอนที่สำคัญในการปรับตัวให้สามารถจัดการกับมาตรฐานข้อมูลขนาดใหญ่ที่ยุคปัจจุบัน หวังว่าคำแนะนำนี้จะเป็นประโยชน์ในการสร้างทีม Big Data ที่สามารถช่วยองค์กรของคุณในการใช้ข้อมูลขนาดใหญ่ได้มากที่สุด
การสร้าง Data-Driven Culture
เป็นการสร้างรากฐานที่จำเป็นในการลงทุนด้าน Big Data เพราะ ต่อให้เรา Implement Big data platform ขึ้นมาได้สำเร็จจริงๆ แต่หากไม่มีการนำมาใช้งานในการขับเคลื่อนการทำธุรกิจจริง ผู้บริหารไม่ดู Report, ทีมเข้าถึง Data ไม่ได้, ใช้เครื่องมือทำงานไม่สะดวก สุดท้ายแล้วโครงการ Big data นั้นอาจจะยากในการสร้างผลลัพธ์ให้ตรงตาม Business use case ที่เราได้ทำไป เรื่องนี้เป็นเรื่องสำคัญและยากเป็นลำดับที่สอง เพราะมันไม่มีกฎตายตัวในการสร้าง ตัวเลือกในการทำ Data Access Model มี 3 ตัวเลือก
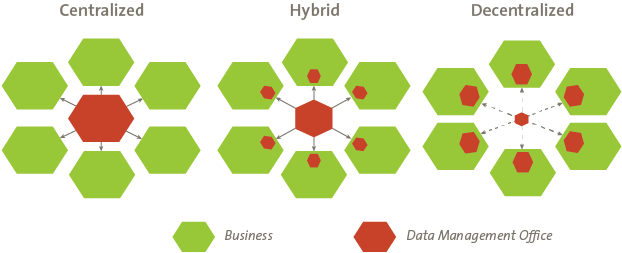
- Centralized model : คือการเอา Data People ทุกคนมาอยู่รวมกันเป็นศูนย์กลางทำงานด้วยกัน Support user จากที่เดียว ข้อดีคือใช้คนน้อยกว่า มีการแบ่งปันความรู้ภายใน ข้อเสียคืออาจจะไม่มีความรู้หน้างานเชิงลึก ทำให้เสียโอกาสในการหา Insight ที่เป็นประโยชน์
- Decentralized model : อันนี้ก็แยกกันไปเลยในแต่ละ Function งานมี Data People เป็นของตนเอง ทำงานแยกกัน ข้อดีคือ สามารถทำงานได้เร็ว เป็นอิสระ มีการเข้าถึงข้อมูลที่เป็นประโยชน์ ข้อเสียคือต้องการคนในจำนวนมาก
- Hybrid model : อันนี้เป็นรูปแบบที่ผมชอบ คือแบ่งงานบางอย่างที่สามารถ Centralized ได้ มาไว้ที่ศูนย์กลาง เช่น งานด้านการสร้าง Data Pipeline, Data Model ให้เป็นหน้าที่ของทีมงานส่วนกลาง และในแต่ละ Function ก็มี Analyst ที่ทำงานวิเคราะห์เชิงลึกของตัวเอง ข้อดีก็ทำให้งานเน้นไปที่ผลลัพธ์ ในการหา Insight ส่วนกลางก็เน้นไปที่การสร้าง Data Platform ให้ดี ข้อเสียคือถ้าไม่มี Data Governance หรือ Policy ที่ดีก็มีความเสี่ยงในเรื่องข้อมูลหลุด เช่น ฝ่ายขายสามารถเข้าถึงข้อมูลเงินเดือน เป็นต้น
จากประสบการณ์ของผู้เขียน Model ที่ประสบความสำเร็จที่สุดในทุกๆ องค์กรที่เคยทำ Data-transformation มาคือ Hybrid Model เพราะการที่จะผลักดันให้องค์กรเป็น Data-driven organization ได้นั้น การมี Data champion จากแต่ละแผนกมาช่วยให้ requirement, อธิบายโจทย์ทางธุรกิจ ทำงานใกล้ชิดกับทีม Data จะช่วยให้ สามารถสร้าง Big Data ที่ตอบโจทย์ความต้องการของ Business user และช่วยให้ทีม Data เข้าใจที่มาและความสำคัญในการออกแบบ Big Data ได้ดีขึ้นครับ
Reference (อ่านเพิมเติม): Data Management activities – Compact
Big Data Project Team
ภายหลังจากเราเลือก Data Access Model ได้แล้ว ขั้นตอนต่อไปคือการสร้างทีม Big Data Project คนที่จะมาช่วย Implement project ให้เกิดขึ้นได้จริง ซึ่งการดำเนินโครงการ Big Data นั้นต้องการความชำนาญในเทคโนโลยี และนอกจากนี้ยังต้องการทักษะในการจัดการโครงการและการวิเคราะห์ข้อมูลที่ซับซ้อน ดังนั้น คุณจำเป็นต้องมีทีมที่มีความสามารถในหลายๆ ด้าน ตำแหน่งงานที่สำคัญในการดำเนินโครงการ Big Data ได้แก่:
- ผู้จัดการโครงการ (Project Manager): คนนี้จะรับผิดชอบในการจัดการโครงการทั้งหมด ตั้งแต่การวางแผนจนถึงการดำเนินการ และการติดตามผล
- วิศวกรข้อมูล (Data Engineer): เป็นคนออกแบบและสร้าง Data pipelines เพื่อนำเข้าข้อมูลจาก หลายๆ Data source มาให้อยู่ในรูปแบบของ Usable data หรือข้อมูลที่สามารถนำไปใช้งานต่อได้ รวมไปจนถึงการออกแบบการเก็บข้อมูลภายใน Big Data platform ด้วย
- นักวิเคราะห์ข้อมูล (Data Analyst): ทำหน้าที่เป็นสะพานระหว่างข้อมูลเชิงเทคนิคและผู้ใช้งานธุรกิจ เขาจะนำข้อมูลที่ซับซ้อนมาเปลี่ยนเป็นข้อมูลที่สามารถเข้าใจและใช้ประโยชน์ได้ ช่วยออกแบบโครงสร้างของ Output ปลายทางของ Data เพื่อนำไปใช้ต่อในการวิเคราะห์
- นักวิเคราะห์ธุรกิจ (Business Analysis): คนนี้จะทำหน้าที่เชื่อมต่อระหว่างทีม Big Data และฝ่ายธุรกิจอื่นๆ ในองค์กร หรือถ้าหากเราเลือกเป็น Hybrid model แล้วตำแหน่งนี้คือคนที่เป็นตัวแทนจากฝั่ง Business เพื่อให้มั่นใจได้ว่าข้อมูลที่จำเป็นในการวเคราะห์เพื่อตัดสินใจนั้นครบถ้วนมากที่สุด
- นักวิทยาศาสตร์ข้อมูล (Data Scientist): คนนี้จะใช้ความรู้เชิงลึกทางสถิติและเครื่องมือการเรียนรู้ของเครื่อง (Machine Learning) เพื่อวิเคราะห์และแปลผลข้อมูลขนาดใหญ่ ให้สามารถนำไปเพิ่มมูลค่าให้กับองค์กรได้ อ่านต่อ Data Science คืออะไร?
การมีทีมที่มีความสามารถและความชำนาญในด้านต่างๆ จะช่วยให้การดำเนินโครงการ Big Data ของคุณมีความสำเร็จมากขึ้น