

Pandas Basics
ในบทนี้เราจะมาเรียนรู้ Basic ของ Pandas กันครับ โดย Key highlight ของ Pandas package โดยบทนี้จะพาทุกคนลองเขียน Code Python เพื่ออ่านข้อมูลจากไฟล์ csv กันครับ
DataFrame & Series
เป็น object ในการจัดเก็บข้อมูลของ Pandas โดยมีอยู่สองประเภทครับ ได้แก่
- DataFrame จะเป็นการจัดเก็บข้อมูลในรูปแบบ Table ที่เราคุ้นเคยครับ คือจะมี Row และ Column ให้เรียกใช้งาน แต่จะมีสิ่งที่เพิ่มเข้ามาคือ Index ให้เรามอง Index เหมือน primary key ใน Table ทั่วไปนั่นเองครับ
- Series Object ประเภท Series จะมีเพียงแค่ Column เดียวครับ โดยถ้าเราเอา Series หลายๆ อันมารวมกัน มันจะกลายเป็น DataFrame ทันที
Object ที่เราจะต้องได้ใช้งานบ่อยที่สุดคือ DataFrame ครับ เรามา Focus ตรงนี้กันก่อนครับผม
Reading the dataset
เรามาเขียน Function ง่ายๆ ในการอ่านข้อมูลจาก CSV มาเก็บลง DataFrame กันดูครับ โดย Dataset ที่เราจำนำมาใช้ทดลองนั้นเป็นของ IBM นะครับ โดยเข้าไปดูรายละเอียดได้ที่ Sales-products-sample-data
หรือสามารถ Download Sample Data set ได้เลย
ข้อมูลที่อยู่ใน Dataset มี Data อยู่ทั้งหมด 88,475 Rows ประกอบไปด้วย 11 Columns ได้แก่
- Retailer country – ประเทศที่อยู่ของร้านค้า
- Order method type – ช่องทางการสั่งซื้อ
- Retailer type – ประเภทร้านค้า
- Product line – หมวดสินค้า
- Product type – หมวดหมู่ย่อยของสินค้า
- Product – ชื่อสินค้า
- Year – ปี
- Quarter – ไตรมาส
- Revenue – ยอดขาย
- Quantity – จำนวนที่ขายได้
- Gross margin – อัตราส่วนกำไรขั้นต้น คำนวณจาก –> (ยอดขาย – ต้นทุน)/ยอดขาย
เรามาเริ่มเขียน Code กันเลยดีกว่าครับ
First Python Code
เริ่มจาก Import Pandas Package ครับ โดยเราตั้งชื่อ ว่า pd เพื่อให้สั้นและเรียกใช้ง่ายครับ
import pandas as pd
read_csv เป็น function ที่ใช้ในการอ่านข้อมูล csv ให้มาอยู่ใน DataFrame Object ครับ โดยเราสร้างตัวแปร df มารับค่าไว้นั่นเองครับ สังเกตว่าใน Python นั้นการสร้างตัวแปรไม่จำเป็นต้องระบุ Data Type ระบบจะจัดการให้อัตโนมัติ
df = pd.read_csv("http://bit.ly/SampleSalesData")
df
เราสามารถแสดงข้อมูลทั้งหมดได้โดย run ชื่อตัวแปร df เราจะเห็นข้อมูลใน DataFrame ของเราได้ครับ และในท้ายตารางจะบอกเราว่ามีข้อมูลกี่ row และกี่ column
หรือเราจะใช้ function head เพื่อแสดงข้อมูล 5 แถวแรก หรือเราจะใช้ function tail เพื่อแสดงข้อมูล 5 แถวสุดท้าย
df.head()
df.tail()
ตัวอย่าง Code
DataFrame Structure
ต่อไปเราจะมาเรียนรู้ในส่วนของ โครงสร้างของ DataFrame กันนะครับ
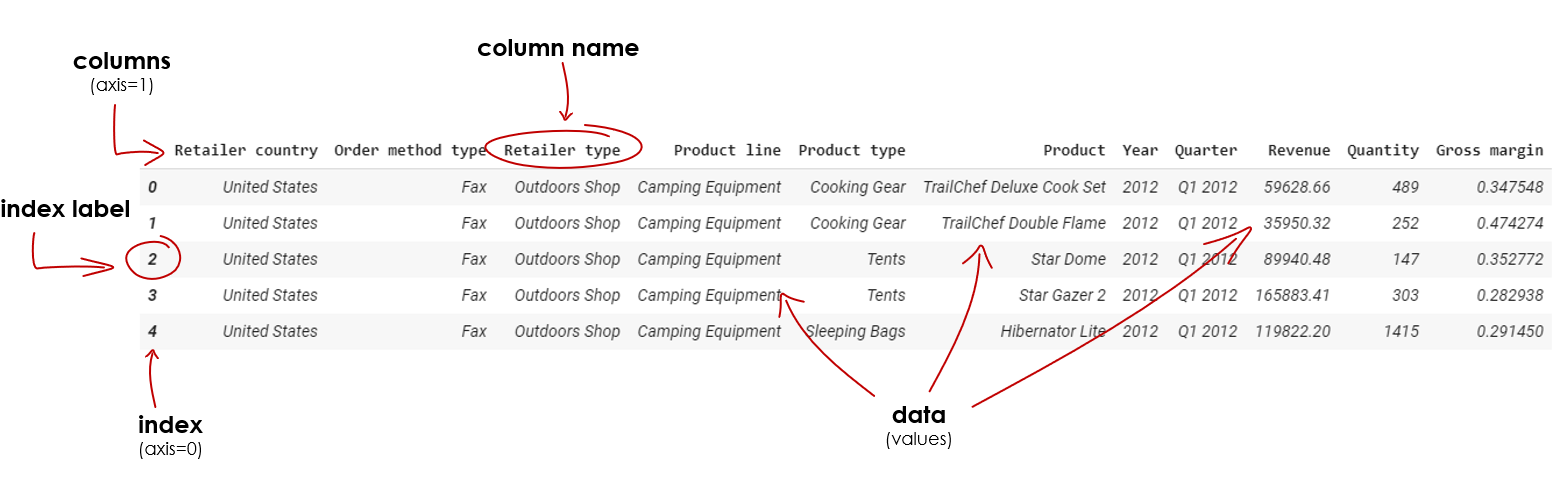
จากตัวอย่าง Data set ของเรา โครงสร้างของ DataFrame ของเราจะประกอบไปด้วย
Columns ทั้งหมด 11 Columns ได้แก่ column name ต่อไปนี้ครับ
- Retailer country
- Order method type
- Retailer type
- Product line
- Product type
- Product
- Year
- Quarter
- Revenue
- Quantity
- Gross margin
เราสามารถใช้คำสั่ง df.columns เพื่อแสดง column ทั้งหมดของ DataFrame ของเรา
ถ้าเราเห็น … ใน DataFrame ของเราแสดงว่ามีข้อมูลซ่อนอยู่นั่นเอง เพราะใน Notebook จะพยายามแสดงข้อมูลเท่าที่จำเป็นให้เราดูครับ
index อย่างที่เคยบอก คือเป็นตัวแยกข้อมูล Row ออกจากกัน หากเราไม่ได้ทำการระบุ index, pandas จะสร้างให้เราอัตโนมัติโดยเริ่มจาก 0, 1, ไปเรื่อยๆ จนถึงแถวสุดท้าย
เราสามารถใช้คำสั่ง df.index เพื่อแสดง index ทั้งหมดของ DataFrame ของเราได้เช่นเดียวกัน
data หรือ value จะแสดงผล font ปกติ ต่างจาก index และ column จะเป็นตัวหนานะครับ และแน่นอนหากไม่ได้ระบุ Data Type pandas จะทำการกำหนด Data Type ให้เราโดยอัตโนมัติ
ในบทต่อไปเราจะมาทบทวนพื้นฐานของ Python กันสักเล็กน้อยก่อนนะครับ